MarshalAs (UnmanagedType.LPStr) — как это преобразовать строки utf-8 в char *
Название вопроса в основном то, что я хотел бы задать:
[MarshalAs(UnmanagedType.LPStr)] Как это преобразует строки UTF-8 в символ *?
Я использую приведенную выше строку, когда пытаюсь установить связь между c # и c ++ dll;
более конкретно, между:
somefunction(char *string) [c++ dll]
somefunction([MarshalAs(UnmanagedType.LPStr) string text) [c#]
Когда я отправляю свой текст utf-8 (scintilla.Text) через c # и в мою c ++ dll,
Я показал в моем отладчике VS 10, что:
-
строка c # была успешно преобразована в
char* -
результирующий
char*правильно отображает соответствующие символы utf-8 (включая бит на корейском языке) в окне просмотра.
Вот скриншот (с более подробной информацией):
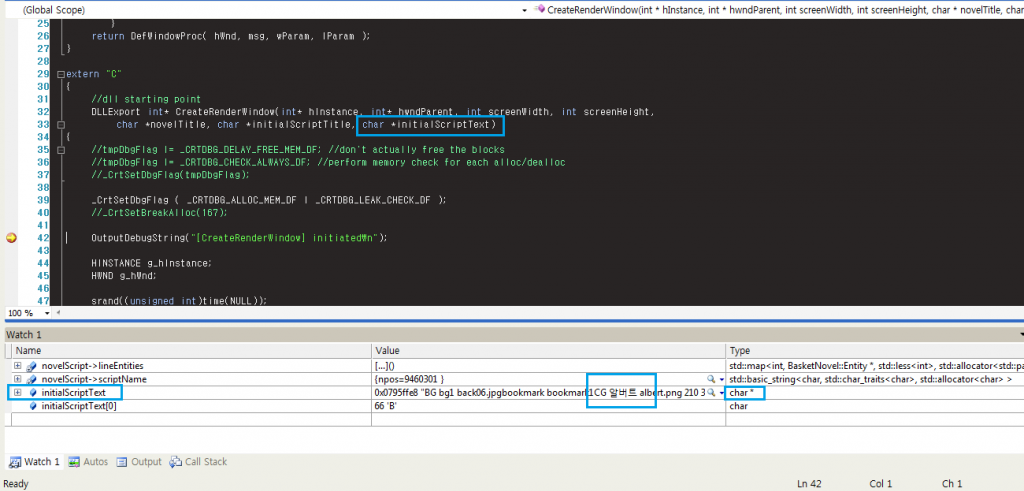
Как вы видете, initialScriptText[0] возвращает сингл byte(char): «B» и содержание char* initialScriptText отображаются правильно (в том числе корейский) в окне просмотра VS.
Проходя через char указатель, похоже, что английский сохранен как единое целое byte в charв то время как корейский, кажется, сохраняется как два байта на char, (корейское слово на скриншоте — 3 буквы, следовательно, сохранено в 6 байтах)
Кажется, это показывает, что каждая «буква» не сохраняется в контейнерах одинакового размера, но отличается в зависимости от языка. (возможный намек на тип?)
Я пытаюсь достичь того же результата в чистом c ++: чтение в файлах utf-8 и сохранение результата как char*,
Вот пример моей попытки прочитать файл utf-8 и преобразовать в char* в с ++:
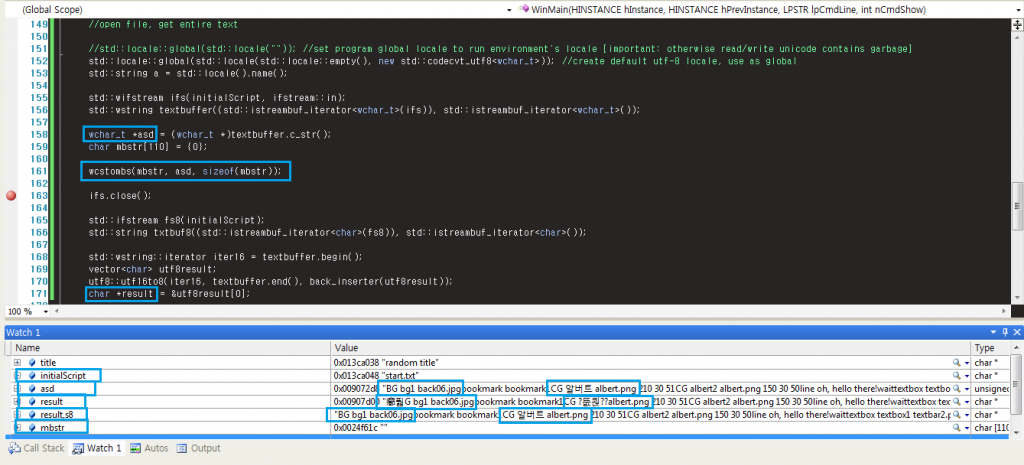
наблюдения:
- потеря в визуальном при преобразовании из
wchar_t*вchar* - так как результат, s8 отображает строку правильно, я знаю, что я преобразовал содержимое файла utf-8 в
wchar_t*успешноchar* - так как ‘result’ сохраняет байты, которые я взял непосредственно из файла, но я получаю результат, отличный от того, что я получил через c # (я использовал тот же файл), я пришел к выводу, что маршал c # поставил содержимое файла с помощью какой-либо другой процедуры для дальнейшего изменения текста в
char*,
(на скриншоте также показана моя ужасная ошибка при использовании wcstombs)
примечание: я использую заголовок utf8 из (http://utfcpp.sourceforge.net/)
Пожалуйста исправьте меня на любые ошибки в моем коде / наблюдениях.
Я хотел бы иметь возможность имитировать результат, который я получаю через маршала c #, и после всего этого я понял, что я полностью застрял. Есть идеи?
Решение
[MarshalAs (UnmanagedType.LPStr)] — как это преобразует строки utf-8 в char *?
Это не так. В управляемом коде нет такого понятия, как «строка utf-8», строки всегда кодируются в utf-16. Маршалинг от и до LPStr выполняется с помощью системной кодовой страницы по умолчанию. Что делает довольно примечательным, что вы видите корейские глифы в отладчике, если только вы не используете кодовую страницу 949.
Если взаимодействие с utf-8 является жестким требованием, вам нужно использовать байт [] в объявлении pinvoke. И конвертировать туда и обратно сами с System.Text.Encoding.UTF8. Используйте его метод GetString () для преобразования byte [] в строку, его метод GetBytes () для преобразования строки в byte []. Избегайте всего этого, если это возможно, используя wchar_t [] в нативном коде.
Другие решения
Если вам нужно маршал UTF-8 string сделать это вручную.
Определить функцию с IntPtr вместо строки:
somefunction(IntPtr text)
Затем преобразуйте текст в массив байтов UTF8 с нулевым символом в конце и запишите их в IntPtr:
byte[] retArray = Encoding.UTF8.GetBytes(text);
byte[] retArrayZ = new byte[retArray.Length + 1];
Array.Copy(retArray, retArrayZ, retArray.Length);
retArrayZ[retArrayZ.Length - 1] = 0;
IntPtr retPtr = AllocHGlobal(retArrayZ.Length);
Marshal.Copy(retArrayZ, 0, retPtr, retArrayZ.Length);
somefunction(retPtr);
Хотя другие ответы верны, в .NET 4.7 произошла серьезная разработка. Теперь есть опция, которая делает именно то, что нужно UTF-8: UnmanagedType.LPUTF8Str, Я попробовал это, и это работает как швейцарский хронометр, делая именно то, на что это похоже.
На самом деле я даже использовал MarshalAs(UnmanagedType.LPUTF8Str) в одном параметре и MarshalAs(UnmanagedType.LPStr) в другой. Также работает. Вот мой метод (принимает строковые параметры и возвращает строку через параметр):
[DllImport("mylib.dll", ExactSpelling = true, CallingConvention = CallingConvention.StdCall)]
public static extern void ProcessContent([MarshalAs(UnmanagedType.LPUTF8Str)]string content,
[MarshalAs(UnmanagedType.LPUTF8Str), Out]StringBuilder outputBuffer,[MarshalAs(UnmanagedType.LPStr)]string settings);
Спасибо, Microsoft! Еще одна неприятность ушла.