Linux широкая строка в многобайтовую проблему
Я знаю, что по этой теме уже задано много вопросов, но здесь я сталкиваюсь с очень необычной ситуацией.
Я работаю в Centos. Мое приложение считывает некоторые данные в wchar_t и преобразует их в многобайтовые (кодировка UTF-8), заполняет буфер char в прототипе сообщения google и отправляет в другое приложение.
Другое приложение снова преобразует его в широкую строку и отображает ее пользователю. Я использую wcstombs для преобразования. Моя локаль «en_US.UTF-8».
Для некоторых строк это работает нормально. Я сталкиваюсь с проблемой в одной конкретной широкой строке (возможно, есть несколько других), в которой wcstombs возвращает -1. Номер ошибки установлен на 84 (неверный или неполный многобайтовый или широкий символ).
Проблема в том, что когда я запускаю свое приложение через Eclipse, преобразование проходит успешно, но когда мое приложение запускается из root (как служба), преобразование не выполняется.
Такое же преобразование строк успешно выполняется в Windows с использованием широкоформатного многобайтового API.
Я не могу понять, почему это происходит.
Надеюсь, что эксперты могут помочь мне.
РЕДАКТИРОВАТЬ
Моя широкая строка — это L «\ 006 £ æ? Jÿ», которая при преобразовании и отображении пользователю становится изображением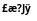
Решение
L"\006" не является допустимой строкой Unicode (ни в UTF-16, ни в UTF-32). я согласен с wcstombsнет соответствующей последовательности UTF-8.
Я подозреваю, что вы не использовали WC_ERR_INVALID_CHARS на винде. Это поймает ту же ошибку.
Другие решения