Компиляция языка высокого уровня в машинный код
Прочитав некоторые ответы с сайта и просмотрев некоторые источники, я подумал, что компилятор преобразует язык высокого уровня (например, C ++) в машинный код, поскольку сам компьютер не должен преобразовывать его в сборку, он только конвертирует его сборка для пользователя, чтобы просмотреть код и может иметь больше контроля над кодом при необходимости.
Но это было найдено в одном из моих лекционных листов, поэтому я был бы признателен, если бы кто-то мог объяснить дальше и исправить меня, если я ошибаюсь, или на скриншоте ниже.
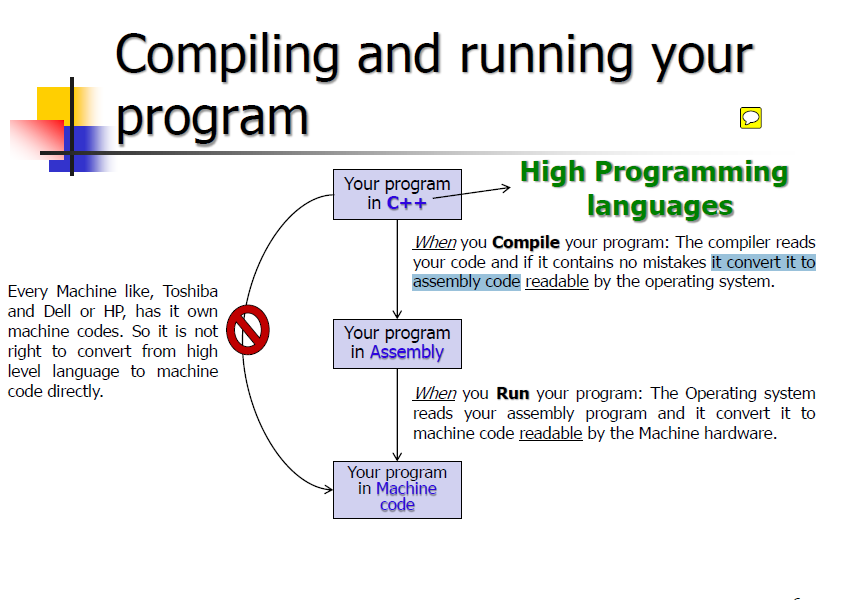
Решение
Ваш слайд в основном неправильный …
Существует взаимно-однозначное соответствие между сборкой и машинным кодом. Сборка — это текстовое представление информации, а машинный код — двоичное представление.
Однако некоторые машины поддерживают дополнительные инструкции по сборке, но какие инструкции включены в созданный код сборки, все еще определяется во время компиляции, а не во время выполнения. В целом, однако, это определяется процессором в системе (intel, amd, ti, nvidia и т. Д.), А не производителем, у которого вы покупаете всю систему.
Другие решения
Этот слайд путает байт-код с текстовой сборкой.
Сборка — это читаемая человеком версия либо байт-кода, либо машинного кода. Машинный код — это то, что аппаратное обеспечение может запускать напрямую. Байт-код далее компилируется в машинный код, он низкоуровневый, но общий.
Некоторые языки используют байт-код, который во время выполнения транслируется в машинный код еще более низкого уровня. Одним из примеров этого является Java, где файлы классов иногда будут компилироваться в машинный код как оптимизация времени выполнения. Другим является cuda, где каждый gvu nvidia имеет свой набор команд, но компилятор cuda генерирует байт-код, который затем может преобразовать драйвер cuda для каждого gpu.
Другой вариант заключается в том, что он говорит о том, как процессоры Intel преобразуют машинный код во время выполнения во внутренний микрокод, а затем запускают его, хотя это совершенно невидимо для программного обеспечения, включая ОС.
Слайд плохо во многих отношениях.
Очень упрощенная версия того, что на самом деле происходит в примере, приведенном на слайде — компиляция C ++ — объяснил бы, что существует четыре фазы компиляции для создания и выполнения из файла исходного кода:
- предварительная обработка
- Сборник «Правильный»
- сборочный
- соединение
в предварительная обработка фаза, директивы препроцессора, такие как #include а также #define полностью раскрыты, а комментарии удалены препроцессор, создание «постобработки» C ++. Слайд опускает это полностью.
в сборник «правильный» фаза, постобработанный текст предыдущего этапа преобразуется в язык ассемблера посредством компилятор. К сожалению, мы используем один и тот же термин — компиляция — как для всей четырехэтапной процедуры, так и для этого одного шага, но так оно и есть.
В отличие от слайда, заявления на языке ассемблера не «Читаемые ОС», и они не преобразуются в машинный код во время выполнения. Скорее они читаются ассемблер, которая делает свою работу (следующий абзац) во время компиляции.
в сборка фаза, операторы языка ассемблера из предыдущего этапа преобразуются в код объекта (инструкции двоичного машинного кода, которые понимает процессор, в сочетании с метаданными, которые понимают ОС и компоновщик) ассемблером.
в соединение На этапе объектный код предыдущего этапа связывается с другими файлами объектного кода и общими / системными библиотеками для формирования исполняемого файла.
Во время выполнения ОС — в частности, погрузчик — читает исполняемый файл в память и выполняет связывание во время выполнения, где ссылки на общие / системные библиотеки разрешаются, и эти библиотеки загружаются в память (если они еще не созданы), чтобы ваш исполняемый файл мог их использовать.
Еще одна ошибка заключается в том, что машины разных марок делают не имеют свои «собственные машинные коды». То, что определяет машинные коды, которые понимает машина, — это процессор. Если две машины имеют одинаковый процессор (например, Dell ноутбук и Тошиба ноутбук с таким же Intel i7-3610QM CPU), то они понимают те же машинные коды. Более того, два ЦП с одинаковой ISA (архитектура набора команд) понимают одинаковые машинные коды. Кроме того, новые процессоры, как правило, обратно совместимы со старыми процессорами той же серии. Например, более новый Intel i7 CPU понимает все инструкции, которые старше Intel Pentium 4 понимает, но не наоборот.
Надеюсь, я нашел несколько лучший баланс между простотой и правильностью, чем слайд выше, который с треском провалился.