Кодирование улучшенного реверсора LSB
Я наткнулся на стеганографическое изображение с разделенной структурой IDAT из 12 блоков (последний LSB немного меньше) (.PNG). Я немного подробнее расскажу о структуре вопроса, прежде чем подойду к сути вопроса, так как мне нужно уточнить некоторые вещи, поэтому, пожалуйста, не помечайте его как не по теме, поскольку это не так. Я просто должен объяснить понятие, стоящее за сценарием, чтобы я мог разобраться в самой проблеме. Это определенно имеет встроенные данные в себя. Данные, похоже, были скрыты путем изменения улучшенный LSB значения, исключающие высокоуровневые биты для каждого пикселя, за исключением последнего младшего значащего бита. Таким образом, все байты будут равны 0 или 1, поскольку 0 или 1 в диапазоне значений 256 не дадут видимого цвета. По сути, 0 остается на 0, а 1 становится максимальным значением, или 255. Я анализировал это изображение многими различными способами, но не вижу ничего странного, кроме полного отсутствия одного значения в любом из трех цветов значения (RGB) и повышенное присутствие другого значения в 1/3 значений цвета. Однако изучение их и замена байтов мне ничего не дало, и я не знаю, стоит ли даже продолжать этот путь.
Следовательно, я смотрю на разработку сценария в довольно питон, PHP или же C / C ++ это полностью изменило бы процесс и «восстановило» расширенные LSB.
Я преобразовал это в 24-битный .BMP и отслеживание красной кривой от стеганализа хи-квадрат, несомненно, что в файле есть стеганографированные данные.


Во-первых, здесь чуть больше 8 вертикальных зон. Это означает, что есть скрытые данные чуть более 8 КБ. Один пиксель может использоваться, чтобы скрыть три бита (один в младшем бите каждого цветового тона RGB). Таким образом, мы можем скрыть (98×225) х3 бит. Чтобы получить количество килобайт, мы делим на 8 и на 1024: ((98×225) x3) / (8×1024). Ну, это должно быть около 8,1 килобайт. Но это не тот случай.
Анализ APPO а также APP1 маркеры .JPG Расширение файла также дает несколько неудобных выводов:
Start Offset: 0x00000000
*** Marker: SOI (xFFD8) ***
OFFSET: 0x00000000
*** Marker: APP0 (xFFE0) ***
OFFSET: 0x00000002
length = 16
identifier = [JFIF]
version = [1.1]
density = 96 x 96 DPI (dots per inch)
thumbnail = 0 x 0
*** Marker: APP1 (xFFE1) ***
OFFSET: 0x00000014
length = 58
Identifier = [Exif]
Identifier TIFF = x[4D 4D 00 2A 00 00 00 08 ]
Endian = Motorola (big)
TAG Mark x002A = x[002A]
EXIF IFD0 @ Absolute x[00000026]
Dir Length = x[0003]
[IFD0.x5110 ] =
[IFD0.x5111 ] = 0
[IFD0.x5112 ] = 0
Offset to Next IFD = [00000000]
*** Marker: DQT (xFFDB) ***
Define a Quantization Table.
OFFSET: 0x00000050
Table length = 67
----
Precision=8 bits
Destination ID=0 (Luminance)
DQT, Row #0: 2 1 1 2 3 5 6 7
DQT, Row #1: 1 1 2 2 3 7 7 7
DQT, Row #2: 2 2 2 3 5 7 8 7
DQT, Row #3: 2 2 3 3 6 10 10 7
DQT, Row #4: 2 3 4 7 8 13 12 9
DQT, Row #5: 3 4 7 8 10 12 14 11
DQT, Row #6: 6 8 9 10 12 15 14 12
DQT, Row #7: 9 11 11 12 13 12 12 12
Approx quality factor = 94.02 (scaling=11.97 variance=1.37)
Я почти убежден, что алгоритм шифрования не применяется, поэтому ни одна из ключевых реализаций не следует за сокрытием. Я имею в виду кодирование сценария, который будет сдвигать значения LSB и возвращать оригиналы. Я проверил файл под несколькими структурными анализами, статистическими атаками, BPCS,
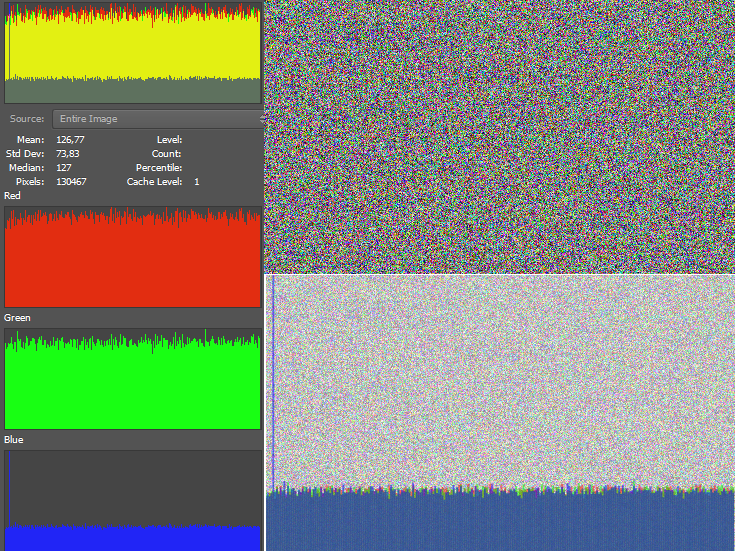
Гистограмма изображения показывает определенный цвет с необычным всплеском. Я манипулировал этим, как мог, чтобы попытаться просмотреть скрытые данные, но безрезультатно. Это гистограммы значений RGB следующим образом:
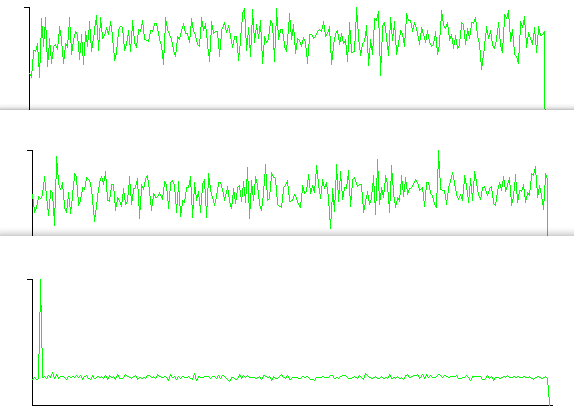
Тогда есть несколько IDAT ломти. Но я собрал похожее изображение, определив случайные цветовые значения в каждом пикселе, и я тоже получил несколько из них. До сих пор я также нашел очень мало внутри них. Еще более интересным является способ повторения значений цвета на изображении. Похоже, что частота повторного использования цветов могла бы помочь. Но мне еще предстоит полностью понять эти отношения, если таковые существуют. Кроме того, существует только один столбец и одна строка пикселей, которые не имеют полного значения 255 на своем альфа-канале. Я даже интерпретировал Икс, Y, , р, г, а также В значения каждого пикселя в изображении как ASCII, но не имеют ничего слишком четкого. Даже зеленая кривая среднего значения LSB не может сказать нам ничего. Там нет очевидного перерыва. Вот несколько других гистограмм, которые показывают странную кривую синего значения из RGB:
Но красная кривая, результат анализа хи-квадрат, показывает некоторую разницу. Это может видеть то, что мы не можем видеть. Статистическое обнаружение более чувствительно, чем наши глаза, и я думаю, это был мой последний пункт. Тем не менее, есть и своего рода задержка в красной кривой. Даже без скрытых данных он начинается с максимума и остается таким в течение некоторого времени. Это близко к ложному срабатыванию. Он выглядит как LSB на изображении и очень близок к случайному, а алгоритму требуется большое количество пользователей (помните, что анализ выполняется по возрастающей совокупности пикселей), прежде чем достигнуть порога, когда он может решить, что на самом деле они не случайные в конце концов, и красная кривая начинает снижаться. Такая же задержка происходит со скрытыми данными. Вы скрываете 1 или 2 КБ, но красная кривая не падает сразу после этого количества данных. Это немного ждет, здесь соответственно около 1,3 кб и 2,6 кб. Вот представление типов данных из шестнадцатеричного редактора:
byte = 166
signed byte = -90
word = 40,358
signed word = -25,178
double word = 3,444,481,446
signed double word = -850,485,850
quad = 3,226,549,723,063,033,254
signed quad = 3,226,549,723,063,033,254
float = -216652384.
double = 5.51490063721e-093
word motorola = 42,653
double word motorola = 2,795,327,181
quad motorola = 12,005,838,827,773,085,484
Вот еще один спектр, чтобы подтвердить поведение значения синего (RGB).
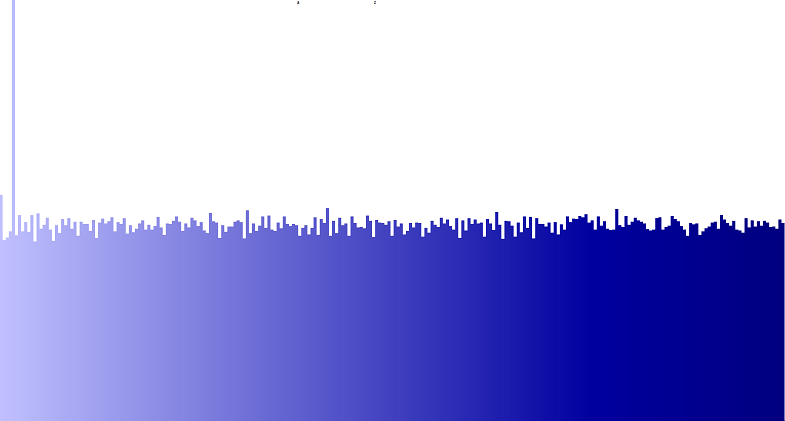
Обратите внимание, что мне нужно было пройти через все это, чтобы прояснить ситуацию и вопросы программирования, которыми я занимаюсь. Это само по себе делает мой вопрос НЕ не по теме, поэтому я был бы рад, если он не будет помечен как таковой. Спасибо.
Решение
В случае изображения с примененным улучшением LSB, я не могу придумать способ вернуть его обратно в исходное состояние, потому что нет понятия о первоначальных значениях RGB. Они установлены на 255 или 0 в зависимости от их младшего значащего бита. Другой вариант, который я вижу здесь, — если это какой-то протокол, включающий квантовую стеганографию.
Matlab и некоторые методы стеганализа могут быть ключом к вашей проблеме.
Вот Ява хи-квадрат класс для некоторого статистического анализа:
private long[] pov = new long[256];
and three methods as
public double[] getExpected() {
double[] result = new double[pov.length / 2];
for (int i = 0; i < result.length; i++) {
double avg = (pov[2 * i] + pov[2 * i + 1]) / 2;
result[i] = avg;
}
return result;
}
public void incPov(int i) {
pov[i]++;
}
public long[] getPov() {
long[] result = new long[pov.length / 2];
for (int i = 0; i < result.length; i++) {
result[i] = pov[2 * i + 1];
}
return result;
или попробуйте с некоторыми побитовыми операциями сдвига как:
int pRGB = image.getRGB(x, y);
int alpha = (pRGB >> 24) & 0xFF;
int blue = (pRGB >> 16) & 0xFF;
int green = (pRGB >> 8) & 0xFF;
int red = pRGB & 0xFF;
Другие решения
Других решений пока нет …