Кодирование более 256 символов с помощью арифметического кодирования
Я пытаюсь кодировать подписанные значения в диапазоне от -256 <-> 255 (т.е. 9-битные данные представлены короткая) с арифметическим кодером, однако я обнаружил, что существующие реализации арифметического кодирования (такие как dlib, РАЕН) обычно читает файл в виде строки и обрабатывает данные как 8-битные.
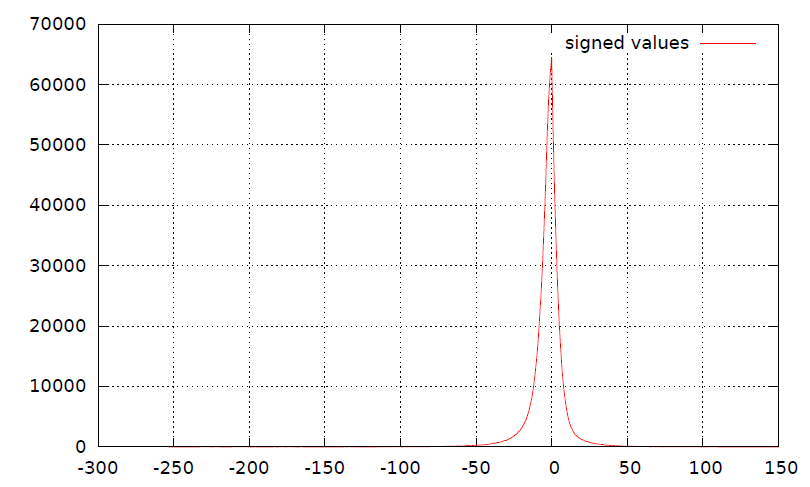
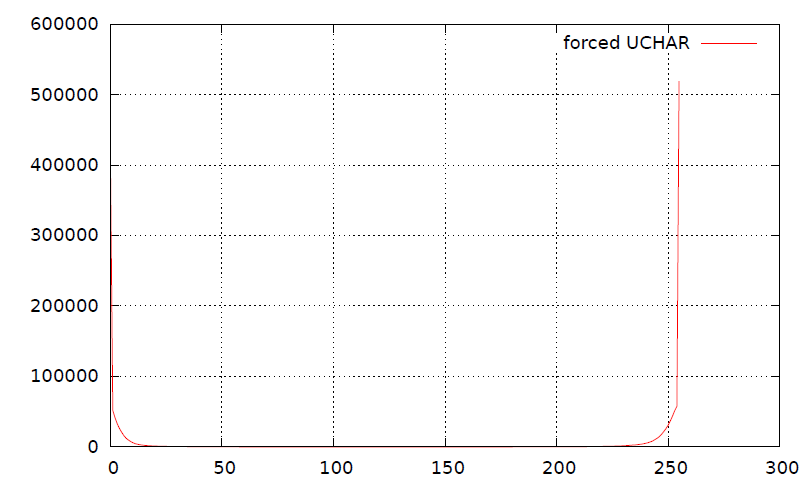
Проблема с этим методом заключается в том, что это разделение подписанных данных (показано в 3) в виде строки разрушает основную гистограмму (показано в 4). Я считаю, что такое разделение может также ухудшить коэффициенты сжатия (но я могу ошибаться).
Я проверил свою гипотезу, реализовав кодировку Хаффмана с 8-битными и 16-битными данными, и обнаружил, что был прав, возможно, это связано с зависимостью Хаффмана от создания дерева с использованием вероятностей.
(ИЗМЕНЕНО). Мой вопрос: как кодировать / моделировать символы (которые не могут содержаться в обычном 8-битном контейнере), чтобы результирующие символы можно было легко сжать с помощью традиционных реализаций арифметического компрессора, не влияя на коэффициенты сжатия.
Подписанная гистограмма:
Расщепленная гистограмма:
Решение
Задача ещё не решена.
Другие решения
Других решений пока нет …