_kmp огромные накладные расходы и время вращения для неизвестных вызовов в OpenMP?
Я использую Intel VTune для анализа моего параллельного приложения.
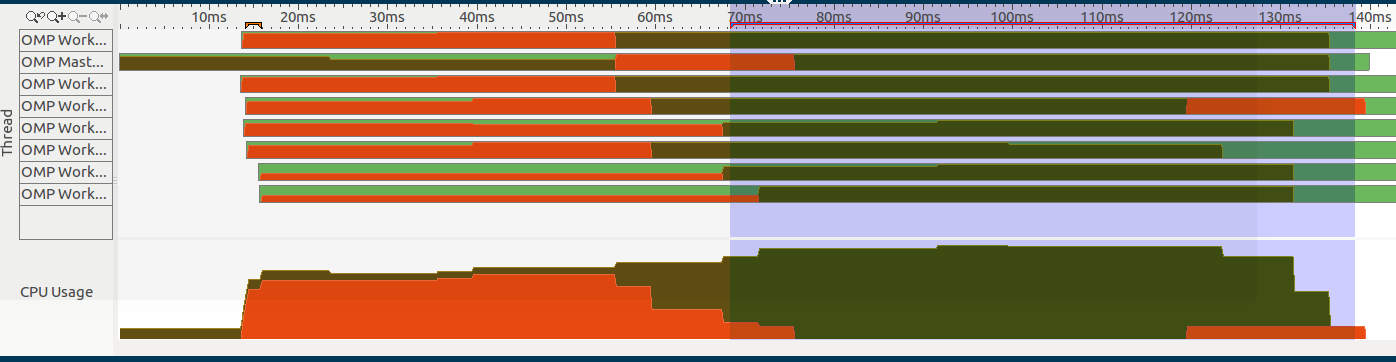
Как видите, в начале приложения есть огромное время вращения (обозначается оранжевой секцией слева):
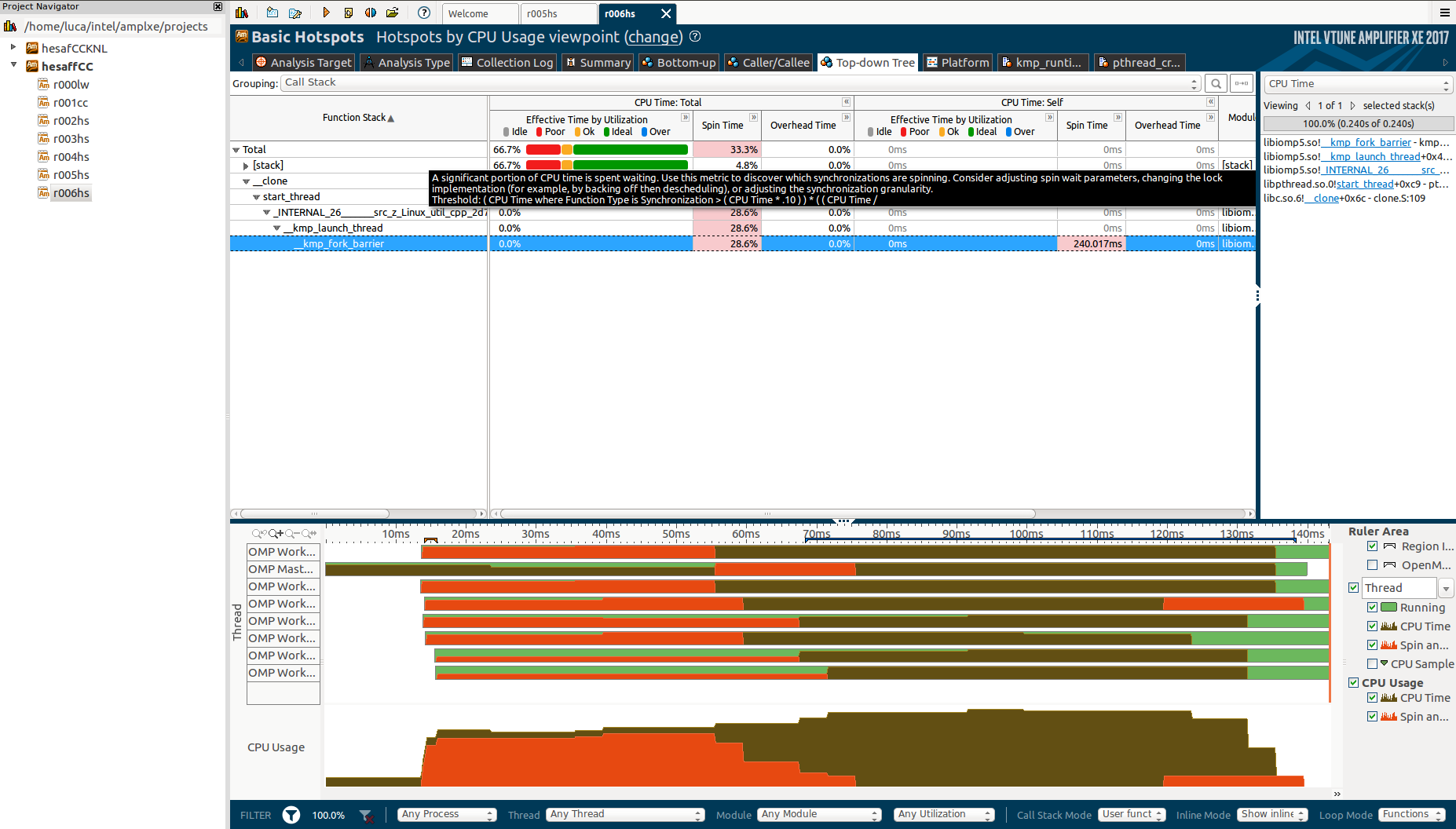
Это более 28% продолжительности приложения (что составляет примерно 0,14 секунды)!
Как видите, эти функции _clone, start_thread, _kmp_launch_thread а также _kmp_fork_barrier и они выглядят как внутренние OpenMP или системные вызовы, но не указано, откуда эти функции вызываются.
Кроме того, если мы увеличим масштаб в начале этого раздела, мы можем заметить экземпляр региона, представленный выбранным регионом:
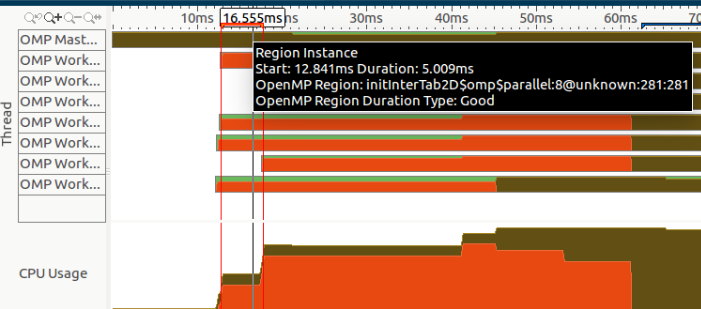
Однако я никогда вызов initInterTab2d и я понятия не имею, вызывается ли он некоторыми библиотеками, которые я использую (особенно OpenCV).
Глубоко копаясь и выполняя анализ Advanced Hotspot, я обнаружил немного больше о первых неизвестных функциях:
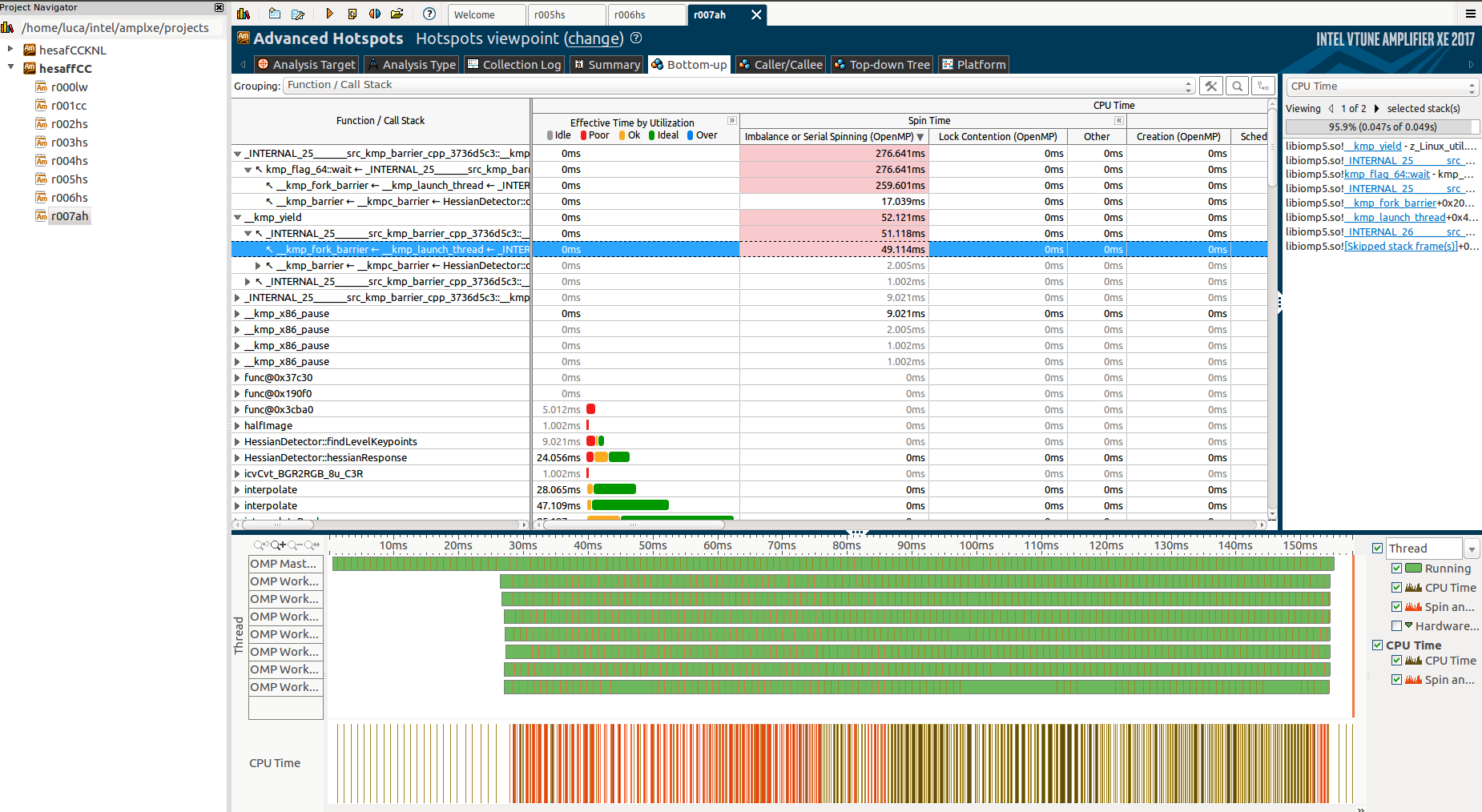
И добавив вкладку Function / Call Stack:
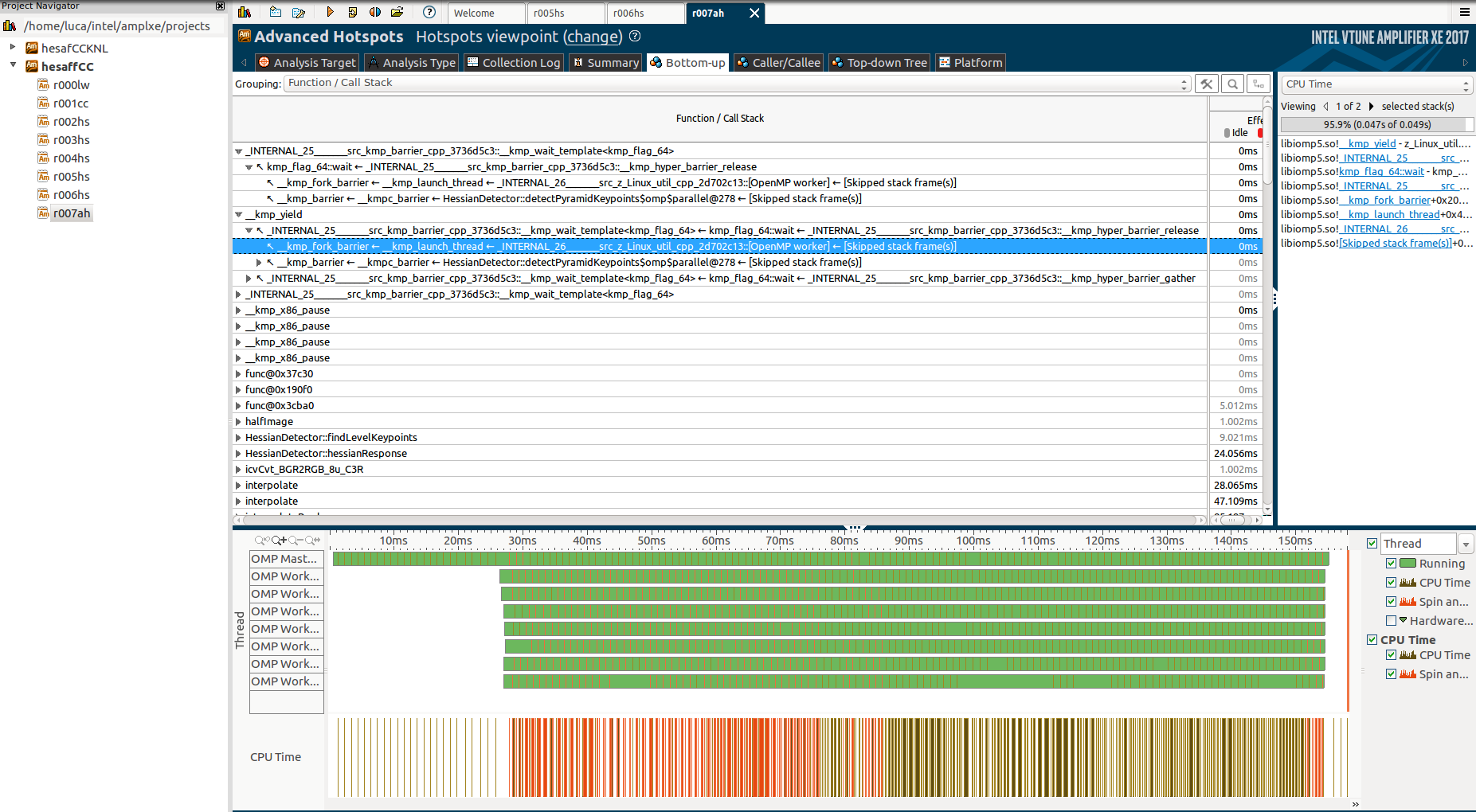
Но опять же, я не могу по-настоящему понять, почему эти функции, почему они занимают так много времени и почему во время них работает только главный поток, в то время как остальные находятся в «барьерном» состоянии.
Если вы заинтересованы, этот это ссылка на часть кода.
Обратите внимание, что у меня есть только один #pragma omp parallel регион, который является выбранным разделом этого изображения (справа):
Структура кода следующая:
- Вычислить некоторые последовательные, не распараллеливающиеся вещи. В частности, рассчитать цепочку размытий, которая представлена
gaussianBlur(включено в конец кода).cv::GaussianBlurявляется функцией OpenCV, которая использует IPP. - Начните параллельный регион, где 3
parallel forиспользуются - Первый звонит
hessianResponse - Один поток добавляет результаты в общий вектор.
- Вторая параллельная область
localfindAffineShapeArgsгенерирует данные, используемые следующей параллельной областью. Две области не могут быть объединены из-за дисбаланса нагрузки. - Третий регион генерирует конечный результат сбалансированным образом.
- Замечания: согласно анализу блокировки VTune,
criticalа такжеbarrierсечения не являются причиной вращения.
Это основная функция кода:
void HessianDetector::detectPyramidKeypoints(const Mat &image, cv::Mat &descriptors, const AffineShapeParams ap, const SIFTDescriptorParams sp)
{
float curSigma = 0.5f;
float pixelDistance = 1.0f;
cv::Mat octaveLayer;
// prepare first octave input image
if (par.initialSigma > curSigma)
{
float sigma = sqrt(par.initialSigma * par.initialSigma - curSigma * curSigma);
octaveLayer = gaussianBlur(image, sigma);
}
// while there is sufficient size of image
int minSize = 2 * par.border + 2;
int rowsCounter = image.rows;
int colsCounter = image.cols;
float sigmaStep = pow(2.0f, 1.0f / (float) par.numberOfScales);
int levels = 0;
while (rowsCounter > minSize && colsCounter > minSize){
rowsCounter/=2; colsCounter/=2;
levels++;
}
int scaleCycles = par.numberOfScales+2;
//-------------------Shared Vectors-------------------
std::vector<Mat> blurs (scaleCycles*levels+1, Mat());
std::vector<Mat> hessResps (levels*scaleCycles+2); //+2 because high needs an extra one
std::vector<Wrapper> localWrappers;
std::vector<FindAffineShapeArgs> findAffineShapeArgs;
localWrappers.reserve(levels*(scaleCycles-2));
vector<float> pixelDistances;
pixelDistances.reserve(levels);
for(int i=0; i<levels; i++){
pixelDistances.push_back(pixelDistance);
pixelDistance*=2;
}
//compute blurs at all layers (not parallelizable)
for(int i=0; i<levels; i++){
blurs[i*scaleCycles+1] = octaveLayer.clone();
for (int j = 1; j < scaleCycles; j++){
float sigma = par.sigmas[j]* sqrt(sigmaStep * sigmaStep - 1.0f);
blurs[j+1+i*scaleCycles] = gaussianBlur(blurs[j+i*scaleCycles], sigma);
if(j == par.numberOfScales)
octaveLayer = halfImage(blurs[j+1+i*scaleCycles]);
}
}
#pragma omp parallel
{
//compute all the hessianResponses
#pragma omp for collapse(2) schedule(dynamic)
for(int i=0; i<levels; i++)
for (int j = 1; j <= scaleCycles; j++)
{
int scaleCyclesLevel = scaleCycles * i;
float curSigma = par.sigmas[j];
hessResps[j+scaleCyclesLevel] = hessianResponse(blurs[j+scaleCyclesLevel], curSigma*curSigma);
}
//we need to allocate here localWrappers to keep alive the reference for FindAffineShapeArgs
#pragma omp single
{
for(int i=0; i<levels; i++)
for (int j = 2; j < scaleCycles; j++){
int scaleCyclesLevel = scaleCycles * i;
localWrappers.push_back(Wrapper(sp, ap, hessResps[j+scaleCyclesLevel-1], hessResps[j+scaleCyclesLevel], hessResps[j+scaleCyclesLevel+1],
blurs[j+scaleCyclesLevel-1], blurs[j+scaleCyclesLevel]));
}
}
std::vector<FindAffineShapeArgs> localfindAffineShapeArgs;
#pragma omp for collapse(2) schedule(dynamic) nowait
for(int i=0; i<levels; i++)
for (int j = 2; j < scaleCycles; j++){
size_t c = (scaleCycles-2) * i +j-2;
//toDo: octaveMap is shared, need synchronization
//if(j==1)
// octaveMap = Mat::zeros(blurs[scaleCyclesLevel+1].rows, blurs[scaleCyclesLevel+1].cols, CV_8UC1);
float curSigma = par.sigmas[j];
// find keypoints in this part of octave for curLevel
findLevelKeypoints(curSigma, pixelDistances[i], localWrappers[c]);
localfindAffineShapeArgs.insert(localfindAffineShapeArgs.end(), localWrappers[c].findAffineShapeArgs.begin(), localWrappers[c].findAffineShapeArgs.end());
}
#pragma omp critical
{
findAffineShapeArgs.insert(findAffineShapeArgs.end(), localfindAffineShapeArgs.begin(), localfindAffineShapeArgs.end());
}
#pragma omp barrier
std::vector<Result> localRes;
#pragma omp for schedule(dynamic) nowait
for(int i=0; i<findAffineShapeArgs.size(); i++){
hessianKeypointCallback->onHessianKeypointDetected(findAffineShapeArgs[i], localRes);
}
#pragma omp critical
{
for(size_t i=0; i<localRes.size(); i++)
descriptors.push_back(localRes[i].descriptor);
}
}
Mat gaussianBlur(const Mat input, const float sigma)
{
Mat ret(input.rows, input.cols, input.type());
int size = (int)(2.0 * 3.0 * sigma + 1.0); if (size % 2 == 0) size++;
GaussianBlur(input, ret, Size(size, size), sigma, sigma, BORDER_REPLICATE);
return ret;
}
Решение
Если вы считаете 50 мс (доля мигания глаза) один раз стоить быть огромные накладные расходы, тогда вы, вероятно, должны сосредоточиться на своем рабочем процессе как таковом. Старайтесь постоянно использовать один полностью инициализированный процесс (с его потоками и структурами данных), чтобы увеличить объем работы, выполняемой при каждом запуске.
Тем не менее, может быть возможно уменьшить накладные расходы, но в любом случае вы будете сильно зависеть от времени выполнения и стоимости инициализации вашей библиотеки, что ограничит переносимость вашей производительности.
Ваш анализ производительности также может быть проблематичным. AFAIK VTune использует выборку, ваши данные указывают интервал выборки 1 мс. Это означает, что у вас может быть всего 50 выборок в течение критического пути инициализации вашего приложения, слишком мало для достоверного анализа. VTune также может иметь некоторые формы инструментария OpenMP, которые обеспечивают более точные результаты в небольших временных масштабах. В любом случае я проводил бы любое измерение производительности всего за 150 мсек с крошкой соли, если бы я не знал точно, какое влияние и метод оказывает измерение.
Постскриптум Запуск простого кода, такого как:
#include <stdio.h>
#include <omp.h>
int main() {
double start = omp_get_wtime();
#pragma omp parallel
{
#pragma omp barrier
#pragma omp master
printf("%f s\n", omp_get_wtime() - start);
}
}
Показывает начальные накладные расходы на создание потока от 3 мс до 200 мс в разных системах / число потоков с помощью среды выполнения Intel OpenMP.
Другие решения
Других решений пока нет …