Как вводить и получать состояние LSTM в тензорном потоке C / Stack Overflow
Я хотел бы построить и обучить многослойную модель LSTM (stateIsTuple = True) на Python, а затем загрузить и использовать ее в C ++. Но мне трудно понять, как кормить и получать состояния в C ++, в основном потому, что у меня нет строковых имен, на которые я могу ссылаться.
Например. Я помещаю начальное состояние в именованную область, такую как
with tf.name_scope('rnn_input_state'):
self.initial_state = cell.zero_state(args.batch_size, tf.float32)
и это показано на графике, как показано ниже, но как я могу кормить их в C ++?
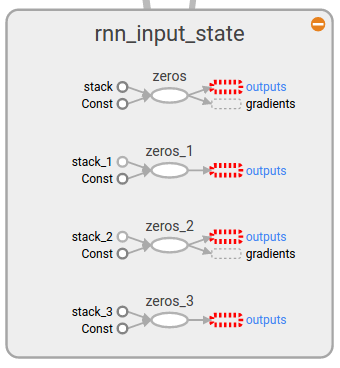
Кроме того, как я могу получить текущее состояние в C ++? Я попробовал код построения графа ниже в python, но я не уверен, что это правильно, потому что last_state должен быть кортежем тензоров, а не одного тензора (хотя я вижу, что узел last_state в тензорной доске равен 2x2x50x128, звучит так, как будто он просто объединяет состояния, так как у меня есть 2 слоя, размер 128 рн, размер мини-пакета 50 и ячейка lstm — с 2 векторами состояний).
with tf.name_scope('outputs'):
outputs, last_state = legacy_seq2seq.rnn_decoder(inputs, self.initial_state, cell, loop_function=loop if infer else None)
output = tf.reshape(tf.concat(outputs, 1), [-1, args.rnn_size], name='output')
и вот как это выглядит в тензорной доске
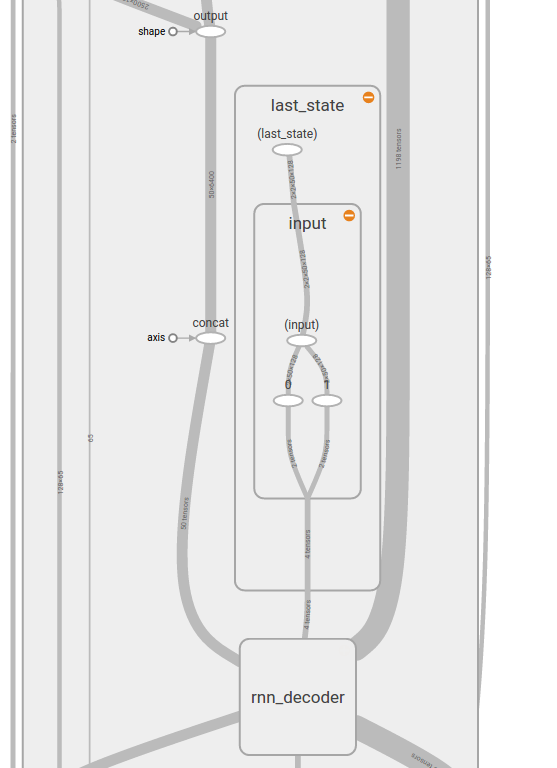
Должен ли я объединять и разбивать тензоры состояний, чтобы входил и выходил только один тензор состояний? Или есть лучший способ?
Постскриптум В идеале решение не должно включать жесткое кодирование количества слоев (или размера rnn). Таким образом, у меня может быть только четыре строки: input_node_name, output_node_name, input_state_name, output_state_name, а остальная часть получена оттуда.
Решение
Мне удалось сделать это, вручную объединив состояние в единый тензор. Я не уверен, если это разумно, так как это как тензорный поток используемый для обработки состояний, но теперь не одобряет это и переключается в состояния кортежей. Вместо установки state_is_tuple = False и риска того, что мой код скоро устареет, я добавил дополнительные операции для ручного суммирования и разборки состояний для одного и того же тензора. Сказав это, он отлично работает как в Python, так и в C ++.
Код ключа:
# setting up
zero_state = cell.zero_state(batch_size, tf.float32)
state_in = tf.identity(zero_state, name='state_in')
# based on https://medium.com/@erikhallstrm/using-the-tensorflow-multilayered-lstm-api-f6e7da7bbe40#.zhg4zwteg
state_per_layer_list = tf.unstack(state_in, axis=0)
state_in_tuple = tuple(
# TODO make this not hard-coded to LSTM
[tf.contrib.rnn.LSTMStateTuple(state_per_layer_list[idx][0], state_per_layer_list[idx][1])
for idx in range(num_layers)]
)
outputs, state_out_tuple = legacy_seq2seq.rnn_decoder(inputs, state_in_tuple, cell, loop_function=loop if infer else None)
state_out = tf.identity(state_out_tuple, name='state_out')
# running (training or inference)
state = sess.run('state_in:0') # zero state
loop:
feed = {'data_in:0': x, 'state_in:0': state}
[y, state] = sess.run(['data_out:0', 'state_out:0'], feed)
Вот полный код, если кому-то это нужно
https://github.com/memo/char-rnn-tensorflow
Другие решения
Других решений пока нет …