Как работает поиск приближения
[Вводная]
это Q& предназначен для более четкого объяснения внутренней работы моего класса поиска приближений, который я впервые опубликовал здесь
Меня уже несколько раз запрашивали более подробную информацию об этом (по разным причинам), поэтому я решил написать Q& тема стиля об этом, которую я могу легко сослаться в будущем и не нужно объяснять это снова и снова.
[Вопрос]
Как приблизить значения / параметры в реальном домене (double) добиться подгонки полиномов, параметрических функций или решения (сложных) уравнений (например, трансцендентных)?
ограничения
- реальный домен (
doubleточность) - C ++ язык
- настраиваемая точность приближения
- известный интервал для поиска
- установленное значение / параметр не является строго монотонным или не функционирует вообще
Решение
Поиск аппроксимации
Это аналогия с бинарным поиском, но без ограничений поиск функции / значения / параметра должен быть строго монотонной функцией при совместном использовании O(n.log(n)) сложность.
Например, допустим следующую проблему
Мы знали функцию y=f(x) и хочу найти x0 такой, что y0=f(x0), Это может быть сделано в основном обратной функцией f но есть много функций, которые мы не знаем, как вычислить обратное к нему. Так как рассчитать это в таком случае?
knowns
y=f(x)— функция вводаy0— хотелyзначениеa0,a1— решениеxинтервал интервалов
Unknowns
x0— хотелxзначение должно быть в диапазонеx0=<a0,a1>
Алгоритм
-
исследовать некоторые точки
x(i)=<a0,a1>равномерно рассредоточены по дальности с шагомdaТак например
x(i)=a0+i*daгдеi={ 0,1,2,3... } -
для каждого
x(i)вычислить расстояние / ошибкуeeизy=f(x(i))Это может быть вычислено, например, так:
ee=fabs(f(x(i))-y0)но можно использовать и любые другие метрики. -
запомни
aa=x(i)с минимальным расстоянием / ошибкойee -
остановиться когда
x(i)>a1 -
рекурсивно увеличить точность
поэтому сначала ограничьте диапазон для поиска только вокруг найденного решения, например:
a0'=aa-da; a1'=aa+da;затем увеличьте точность поиска, уменьшив шаг поиска:
da'=0.1*da;если
da'не слишком мало или если максимальное число рекурсий не достигнуто, перейдите к # 1 -
найденное решение находится в
aa
Вот что я имею в виду:
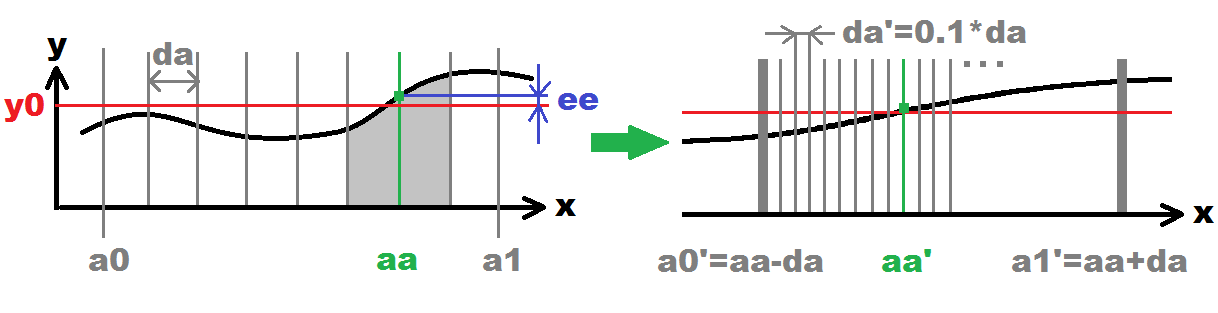
С левой стороны показан начальный поиск (пули # 1, # 2, # 3, # 4). На правой стороне следующий рекурсивный поиск (пуля # 5). Это будет рекурсивно зацикливаться, пока не будет достигнута желаемая точность (количество рекурсий). Каждая рекурсия увеличивает точность 10 раз (0.1*da). Серые вертикальные линии представляют собой зондирующие x(i) точки.
Вот исходный код C ++ для этого:
//---------------------------------------------------------------------------
//--- approx ver: 1.01 ------------------------------------------------------
//---------------------------------------------------------------------------
#ifndef _approx_h
#define _approx_h
#include <math.h>
//---------------------------------------------------------------------------
class approx
{
public:
double a,aa,a0,a1,da,*e,e0;
int i,n;
bool done,stop;
approx() { a=0.0; aa=0.0; a0=0.0; a1=1.0; da=0.1; e=NULL; e0=NULL; i=0; n=5; done=true; }
approx(approx& a) { *this=a; }
~approx() {}
approx* operator = (const approx *a) { *this=*a; return this; }
//approx* operator = (const approx &a) { ...copy... return this; }
void init(double _a0,double _a1,double _da,int _n,double *_e)
{
if (_a0<=_a1) { a0=_a0; a1=_a1; }
else { a0=_a1; a1=_a0; }
da=fabs(_da);
n =_n ;
e =_e ;
e0=-1.0;
i=0; a=a0; aa=a0;
done=false; stop=false;
}
void step()
{
if ((e0<0.0)||(e0>*e)) { e0=*e; aa=a; } // better solution
if (stop) // increase accuracy
{
i++; if (i>=n) { done=true; a=aa; return; } // final solution
a0=aa-fabs(da);
a1=aa+fabs(da);
a=a0; da*=0.1;
a0+=da; a1-=da;
stop=false;
}
else{
a+=da; if (a>a1) { a=a1; stop=true; } // next point
}
}
};
//---------------------------------------------------------------------------
#endif
//---------------------------------------------------------------------------
Вот как это использовать:
approx aa;
double ee,x,y,x0,y0=here_your_known_value;
// a0, a1, da,n, ee
for (aa.init(0.0,10.0,0.1,6,&ee); !aa.done; aa.step())
{
x = aa.a; // this is x(i)
y = f(x) // here compute the y value for whatever you want to fit
ee = fabs(y-y0); // compute error of solution for the approximation search
}
в реме выше for (aa.init(... операнд по имени. a0,a1 интервал, на котором x(i) прощупывается, da это начальный шаг между x(i) а также n количество рекурсий так что если n=6 а также da=0.1 окончательная максимальная ошибка x подходит будет ~0.1/10^6=0.0000001, &ee указатель на переменную, где будет вычислена фактическая ошибка Я выбираю указатель, чтобы при этом не возникало коллизий.
[заметки]
Этот приближенный поиск может быть вложен в любую размерность (но, грубо говоря, нужно быть осторожным со скоростью), посмотрите несколько примеров
- Приближение n точек к кривой с наилучшим соответствием
- Кривая соответствует точкам y на повторяющихся позициях x (спиральные рукава Galaxy)
- Повышение точности решения трансцендентного уравнения
- Найти эллипс минимальной площади, содержащий множество точек в c ++
В случае несоответствия функции и необходимости получения «всех» решений вы можете использовать рекурсивное подразделение интервала поиска после найденного решения, чтобы проверить другое решение. Смотрите пример:
Что вы должны знать?
Вы должны тщательно выбрать интервал поиска <a0,a1> поэтому он содержит решение, но не слишком широк (или будет медленным). Также начальный шаг da очень важно, если он слишком велик, вы можете пропустить локальные минимальные / максимальные решения, или если он слишком мал, вещь станет слишком медленной (особенно для вложенных многомерных подборок).
Другие решения
сочетание секущий а также деление пополам метод намного лучше:
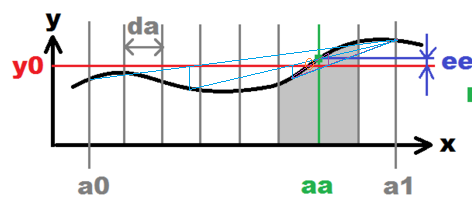
мы находим корневые аппроксимации секансами и держим корень в скобках, как при делении пополам.

всегда держите два ребра интервала так, чтобы дельта на одном ребре была отрицательной, а на другом — положительной, чтобы корень гарантированно находился внутри; и вместо деления пополам используйте секущий метод.
псевдокод:
given a function f
given two points a, b, such that a < b and sign(f(a)) /= sign(f(b))
given tolerance tol
find root z of f such that abs(f(z)) < tol -- stop_condition
DO:
x = root of f by linear interpolation of f between a and b
m = midpoint between a and b
if stop_condition holds at x or m, set z and STOP
[a,b] := [a,x,m,b].sort.choose_shortest_interval_with_
_opposite_signs_at_its_ends
Это, очевидно, вдвое интервал [a,b]или даже лучше, на каждой итерации; так что, если функция не очень плохо себя ведет (как, скажем, sin(1/x) возле x=0), это будет сходиться очень быстро, принимая только две оценки f самое большее для каждого шага итерации.
И мы можем обнаружить случаи плохого поведения, проверив, что b-a не становится слишком маленьким (особенно если мы работаем с конечной точностью, как в удвоениях).