Как я могу заставить эту функцию параллельной суммы использовать векторные инструкции?
Как своего рода побочный проект, я работаю над многопоточным алгоритмом суммирования, который превзойдет std::accumulate при работе на достаточно большом массиве. Сначала я опишу свой мыслительный процесс, ведущий к этому, но если вы хотите сразу перейти к проблеме, не стесняйтесь прокрутить вниз до этой части.
В сети я нашел много параллельных алгоритмов сумм, большинство из которых используют следующий подход:
template <typename T, typename IT>
T parallel_sum(IT _begin, IT _end, T _init) {
const auto size = distance(_begin, _end);
static const auto n = thread::hardware_concurrency();
if (size < 10000 || n == 1) return accumulate(_begin, _end, _init);
vector<future<T>> partials;
partials.reserve(n);
auto chunkSize = size / n;
for (unsigned i{ 0 }; i < n; i++) {
partials.push_back(async(launch::async, [](IT _b, IT _e){
return accumulate(_b, _e, T{0});
}, next(_begin, i*chunkSize), (i==n-1)?_end:next(_begin, (i+1)*chunkSize)));
}
for (auto& f : partials) _init += f.get();
return _init;
}
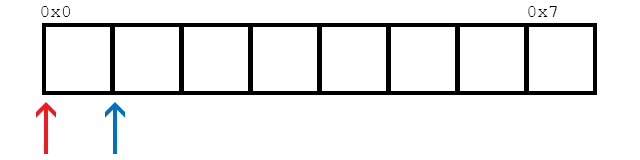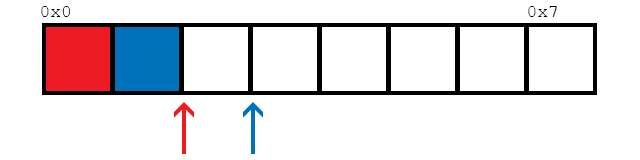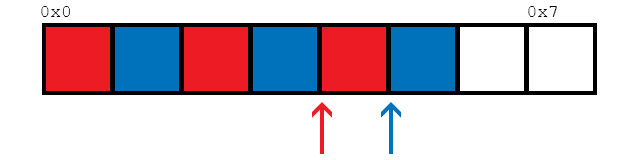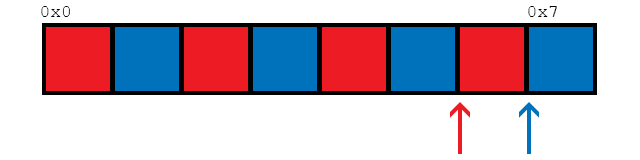
Предполагая, что доступно 2 потока (как сообщает thread::hardware_concurrency()), эта функция будет обращаться к элементам в памяти следующим образом:
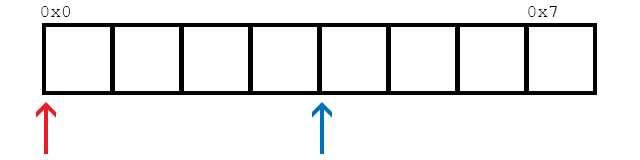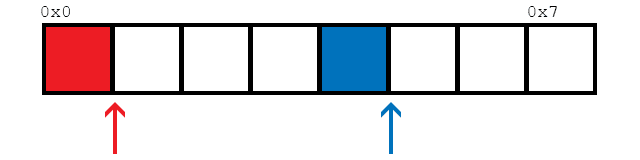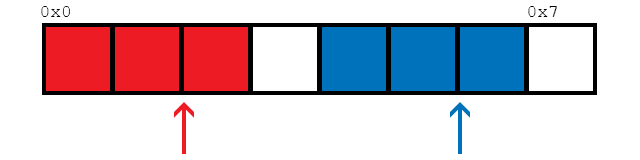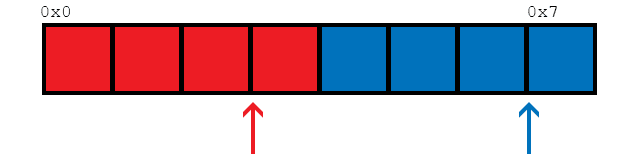
В качестве простого примера, мы смотрим на 8 элементов здесь. Две нити обозначены красным и синим. Стрелки показывают расположение потоков, которые хотят загрузить данные. Как только ячейки становятся красными или синими, они загружаются соответствующим потоком.
Этот подход (по крайней мере, на мой взгляд) не самый лучший, поскольку потоки загружают данные из разных частей памяти одновременно. Если у вас много потоков обработки, скажем, 16 на 8-ядерном гиперпоточном процессоре, или даже больше, то процессору предварительной выборки процессора будет очень трудно справиться со всеми этими операциями чтения из совершенно разных частей памяти (при условии массива слишком большой, чтобы поместиться в кэш). Вот почему я думаю, что второй пример должен будь быстрее:
template <typename T, typename IT>
T parallel_sum2(IT _begin, IT _end, T _init) {
const auto size = distance(_begin, _end);
static const auto n = thread::hardware_concurrency();
if (size < 10000 || n == 1) return accumulate(_begin, _end, _init);
vector<future<T>> partials;
partials.reserve(n);
for (unsigned i{ 0 }; i < n; i++) {
partials.push_back(async(launch::async, [](IT _b, IT _e, unsigned _s){
T _ret{ 0 };
for (; _b < _e; advance(_b, _s)) _ret += *_b;
return _ret;
}, next(_begin, i), _end, n));
}
for (auto& f : partials) _init += f.get();
return _init;
}
Эта функция обращается к памяти своего рода последовательным образом, например так:
Таким образом, средство предварительной выборки всегда может быть впереди, поскольку все потоки обращаются к одной и той же части памяти, поэтому должно быть меньше пропусков кэша и более быстрое время загрузки по всем, по крайней мере, мне так кажется.
Эта проблема в том, что, хотя в теории все в порядке, но фактически скомпилированные версии показывают другой результат. Второй способ намного медленнее. Я немного углубился в проблему и обнаружил, что код сборки, который создается для фактического добавления, очень отличается. Это «горячие петли» в каждом, которые выполняют сложение (помните, что первый использует std::accumulate внутренне, так что вы в основном смотрите на это):
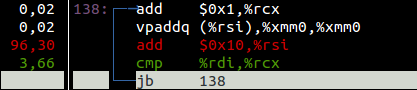

Пожалуйста, игнорируйте проценты и цвета, мой профилировщик иногда ошибается.
Я заметил, что std::accumulate при компиляции использует векторную инструкцию AVX2, vpaddq, Это может добавить четыре 64-разрядных целых числа одновременно. Я думаю, что причина, по которой вторая версия не может быть векторизована, заключается в том, что каждый поток обращается только к одному элементу за раз, а затем пропускает некоторые. Добавление вектора будет загружать несколько смежных элементов, а затем складывать их вместе. Ясно, что это невозможно сделать, поскольку потоки не загружают элементы непрерывно. Я попытался вручную развернуть цикл for во второй версии, и эта векторная инструкция появилась в сборке, но по какой-то причине все это стало мучительно медленным.
Приведенные выше результаты и код сборки получены из версии, скомпилированной gcc, но такое же поведение можно наблюдать и в Visual Studio 2015, хотя я не смотрел на сборку, которую она производит.
Так есть ли способ воспользоваться векторными инструкциями, сохранив эту модель последовательного доступа к памяти? Или этот метод доступа к памяти может помочь при сравнении с первой версией функции?
Я написал немного эталонная программа, который готов к компиляции и запуску, на тот случай, если вы захотите увидеть производительность самостоятельно.
PS: мое основное целевое оборудование — современный x86_64 (вроде haswell и тому подобное).
Решение
Каждое ядро имеет свой кеш и предварительную выборку.
Вы должны смотреть на каждый поток как на независимо выполняемую программу. В этом случае недостатки второго подхода будут очевидны: вы не получаете доступ к последовательным данным в одном потоке. Есть отверстия, которые не должны обрабатываться, поэтому поток не может использовать векторные инструкции.
Другая проблема: процессор предварительно выбирает данные порциями. Из-за того, как работают разные уровни кэша, изменение некоторых данных в метках фрагментов, которые устарели в кэше, и, если другое ядро пытается выполнить какую-либо операцию с тем же фрагментом данных, потребуется подождать, пока первое ядро запишет изменения, и снова получить этот фрагмент. По сути, в вашем втором примере кэш-память всегда устарела, и вы видите производительность необработанного доступа к памяти.
Лучший способ справиться с параллельной обработкой — это обрабатывать данные большими последовательными порциями.
Другие решения
Других решений пока нет …