Как интерпретировать блокировки и ожидания Intel VTune Amplifier
Я пытаюсь распараллелить одну точку моей программы на C ++ с OpenMP, но она не масштабируется. В то время как это требует 25 секунд для 1 потока, я достигаю только 21 секунды для 2 потоков. Я сделал Замки & Ждите анализа с Intel VTune Amplifier, но это не очень мне помогает. Это выглядит как:

Я особенно не понимаю, откуда берется mkl_blas_dcopy и как он его вызывает (даже если я удалю свой параллельный регион, у меня будет этот вызов и второй поток на временной шкале).
Я пытался получить больше информации из дерева сверху вниз, но это не очень полезно для меня.
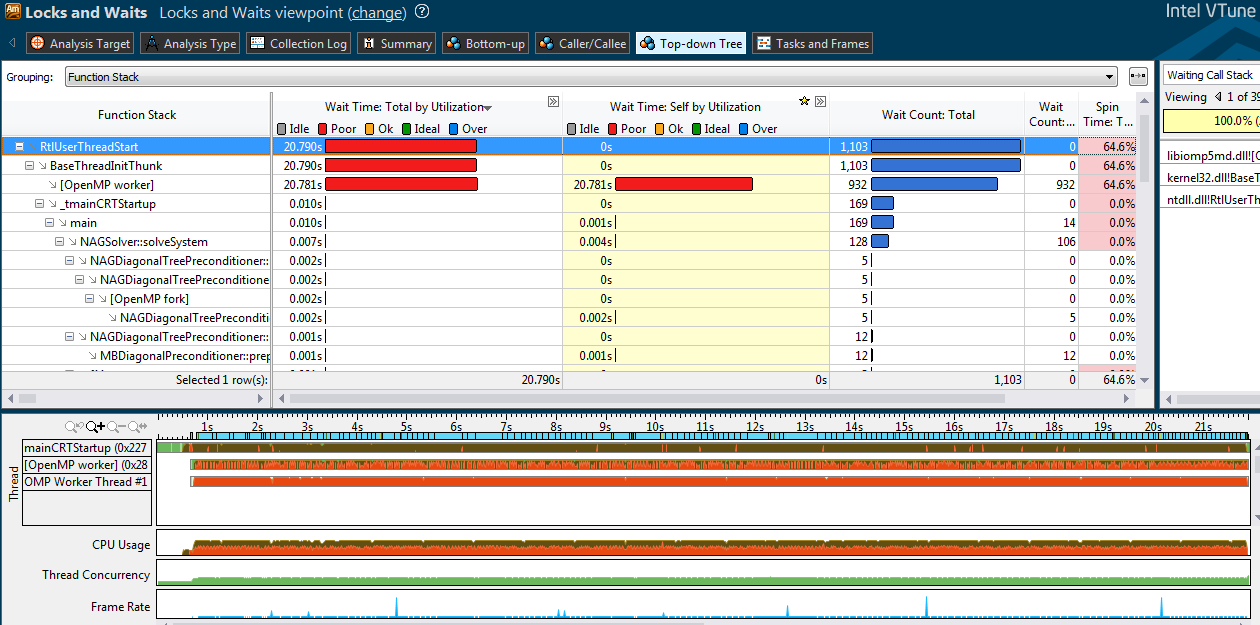
Расширенный анализ горячих точек также не дал мне больше информации.
Как мне подойти к этой проблеме, чтобы определить проблему?
Дополнительная информация: Раньше у меня было намного худшее общее время выполнения, но я много оптимизировал последовательный код и мог повысить производительность, но после этого мой код больше не масштабировался.
Спасибо заранее!
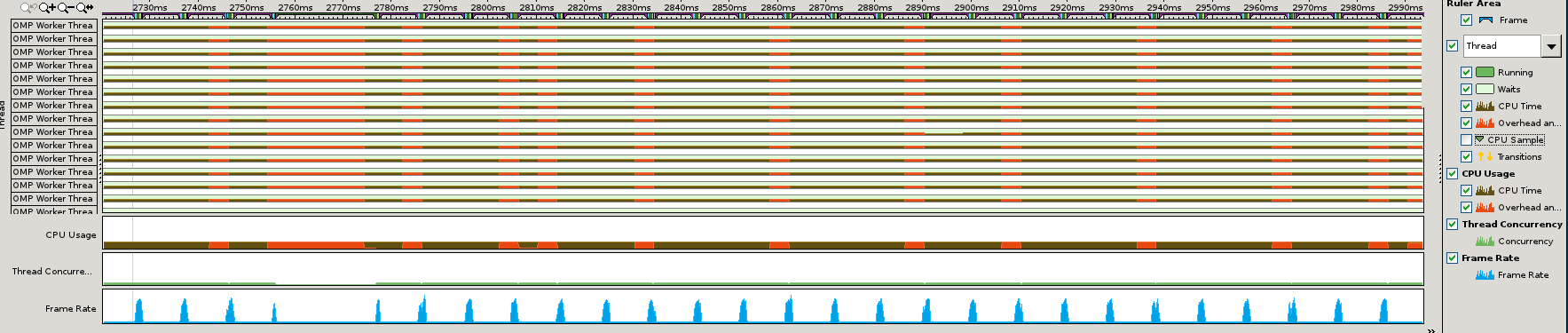
Изменить: Здесь также временная шкала, где не отображаются переходы, независимо от того, как близко я увеличить. В этом случае я использовал другой тестовый случай с 8 потоками.
Решение
- Какую версию VTune вы используете? Похоже, не последний — частота кадров для регионов OpenMP, которая на вашем скриншоте, удалена в текущей версии. Стоит попробовать новое обновление 2015 года 1, были сделаны некоторые исправления и улучшения для анализа OpenMP.
- Какой компилятор и среду выполнения OpenMP вы используете? Если это Intel OpenMP (и компилятор), анализ VTune будет гораздо более информативным для регионов OpenMP. Просто измените группировку снизу вверх с «Funcion / callstack» на «OpenMP region / …» — и вы найдете много интересного.
- Вы видите mkl_blas_dcopy, потому что вы, кажется, используете функции MKL в своем коде. mkl_blas_dcopy — это просто внутренняя функция MKL. Вы можете найти фактический MKL-вызов в своем коде, глядя на панель стека справа, когда точка доступа «mkl_blas_dcopy» выбрана снизу вверх — вы должны увидеть цепочку вызовов вплоть до main ().
- MKL уже распараллелен с OpenMP. Возможно, вы поместили вызов MKL в свой собственный регион OpenMP. Если это так, то это не оптимально — OpenMP не годится при вложении. Вы должны выбрать, использовать параллельную версию MKL без OpenMP или последовательную библиотеку MKL внутри параллельной области OpenMP. Вы можете управлять настройкой последовательного / параллельного MKL через связывание, см. MKL Link Advisor: https://software.intel.com/en-us/articles/intel-mkl-link-line-advisor
- Каждый кадр на временной шкале на вашем скриншоте, вероятно, является областью OpenMP от MKL. Кажется, что есть много параллельных областей короткой продолжительности, которые могут указывать на то, что MKL вызывается из цикла. Таким образом, каждая итерация запускается, выполняется и останавливается в параллельной области OpenMP. Действия Start и Stop имеют некоторые накладные расходы, которые рассчитывают на ваше большое время ожидания. Так что, возможно, стоит попробовать последовательную версию MKL во внешнем цикле OpenMP, чтобы избежать повторного входа в параллельные области.
Другие решения
Переходы показаны для объектов синхронизации. В этом случае время ожидания, скорее всего, приходит из среды выполнения OpenMP внутри библиотеки MKL. В VTune вы будете видеть это время как время загрузки и вращения, в более поздних версиях.