Эффективная оценка функции отображения индекса в CUDA
В ядре CUDA мне нужно найти ключ, который сопоставлен с threadIdx.
Отображение может выглядеть так:
ключ -> threadIdx
0 -> {0,1,2,3,4}
1 -> {5,6,7}
2 -> {8,9,10}
…
Каждый ключ k_i сопоставлен с n_i (разные, произвольные n_i с n_i>0 ) потоки.
Ключ будет использоваться для получения соответствующего значения в глобальном массиве. Это значение затем используется в последующих вычислениях в этом ядре.
Отображение может быть построено как кусочно-постоянная функция:
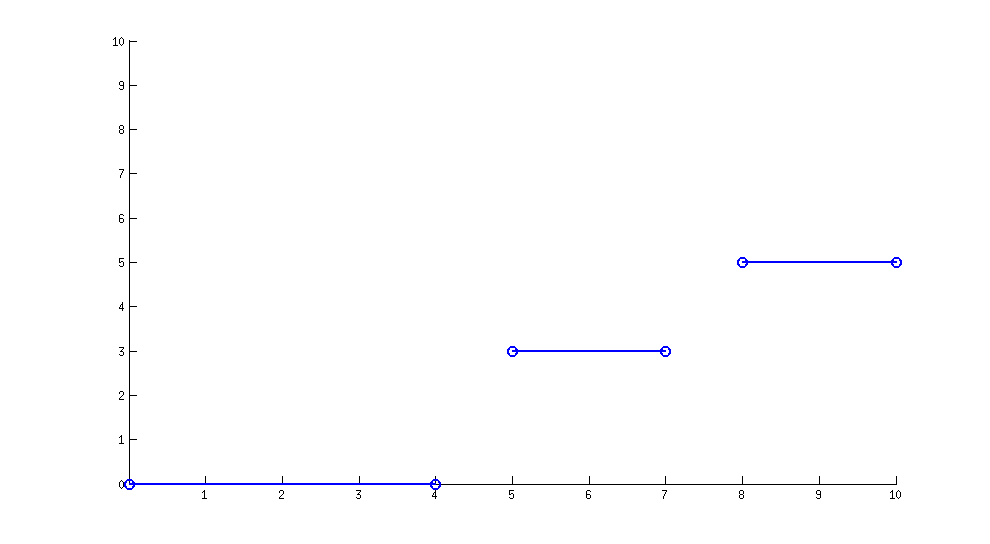
Количество клавиш не ограничено 3 (это только пример!) И известно только во время выполнения, а также соответствующей «ширине» каждой клавиши.
Как я могу продуктивно узнать соответствующий ключ в ядре CUDA?
Я подумал о следующих двух альтернативах:
-
использование бинарного поиска внутри ядра (эффективное использование памяти)
-
предварительный расчет сопоставления для каждого threadIDx, затем запуск ядра (эффективная среда выполнения)
0 0 0 0 0 1 1 1 2 2 2 …
Есть ли лучший способ добиться этого?
Решение
Есть еще один алгоритм, который дает вам что-то среднее с точки зрения эффективности памяти и времени выполнения:
Предположим, что общее количество потоков N, Давайте возьмем номер M это близко к sqrt(N) и разделить все темы на группы по M нить каждого (последний будет неполным). Теперь предварительно вычислим ключ только для первого потока в каждой группе (их идентификаторы будут 0, M, 2M и так далее). Это дает нам O(sqrt(N)) асимптотика памяти.
Теперь в ядре мы можем легко найти индекс текущей группы (groupIdx = threadIdx / M) и следующая группа (groupIdx + 1). Для каждого из них мы знаем заранее рассчитанные ключи key[groupIdx] а также key[groupIdx + 1], Теперь вы можете сделать BS, но принять [key[groupIdx]; key[groupIdx + 1]] сегмент для поиска вместо [1; MAX_KEY_VALUES],
Другие решения
Вы можете объединить — каждый поток, когда он запускается, находит свой собственный ключ с BS и сохраняет его в массиве.