Извлечение текста из документа PDF на основе позиции Переполнение стека
Я пытаюсь извлечь текст из документа PDF на основе его координат, поэтому я столкнулся с двумя понятиями в Adobe PDF Reference (глава 5.3):
- Операторы позиционирования текста
- Текст с отображением операторов
На данный момент я заинтересован в Td & Операторы позиционирования Tm, при использовании Td у тебя есть Техас а также ти, относительно начала текущей строки, которая четко указана в документе PDF:
tx ty Td,
Я использовал этот метод для извлечения текста Техас а также ти координаты. Проблема в том, что я не знаю, как извлечь текст из PDF на основе его позиции, в то время как Техас а также ти.
a b c d e f Tm
это «формула» использования Tm. Что представляют собой значения a-f? Это будет мой вклад для Tm:
BT
/F1 8.88 Tf
0 0 0 rg
0.9998 0 0 1 401.52 448.08 Tm
[<0014>-11<0015>-11<0013>-11<000F>-19<0014>-11<0019>] TJ
ET
Почему у каждой группы из четырех лидирующих 00? это в гексе? я должен преобразовать его из шестнадцатеричного в int и соответствующий символ?
это будет мой вклад для Td:
BT 43.20 421.90 Td 0 Tw /C001 10.00 Tf 0.00 Tw <BlablablaTextInHexThatICanProcess>Tj ET
Это намного понятнее, координаты понятнее.
Как извлечь текст из текстового объекта PDF с позицией Tm на основе простых координат X и Y?
Я использую c ++ и библиотеку PoDoFo
Решение
Прежде всего, при попытке извлекать текст из PDF на основе его позиции, предоставляя только tx и ty, оно делает не достаточно рассмотреть только текстовую матрицу (которую вы устанавливаете, используя Tm Оператор ты уже нашел). Вы также должны учитывать текущую матрицу преобразования!
Я полагаю, когда вы ссылаетесь на позицию, как указано в координаты пространства пользователя по умолчанию.
Чтобы избежать зависящих от устройства эффектов задания объектов в пространстве устройства, PDF определяет независимую от устройства систему координат, которая всегда имеет одинаковое отношение к текущей странице, независимо от устройства вывода, на котором происходит печать или отображение. Эта независимая от устройства система координат называется пользовательским пространством.
Система координат пространства пользователя должна быть инициализирована в состояние по умолчанию для каждой страницы документа. Запись CropBox в словаре страницы должна указывать прямоугольник пользовательского пространства, соответствующий видимой области предполагаемого выходного носителя (окно отображения или печатная страница). Положительная ось x проходит горизонтально вправо, а положительная ось y вертикально вверх
(раздел 8.3.2.3, ISO 32000-1: 2008)
Поскольку мы видим только координаты x и y, мы видим положение как вектор (x, y) в R². Внутренне, однако, PDF-файлы рассматривают эту плоскость, встроенную в R³, с постоянным значением координаты z 1, то есть [x, y, 1]. Это потому, что PDF хочет разрешить многочисленные виды преобразований (переводы, вращения, масштабирование, наклон, …), но, с другой стороны, хочет максимально ограничить необходимые математические операции. Кстати, после вложения нашей плоскости как [x, y, 1] в R³ все эти преобразования возможны с помощью умножения матриц:
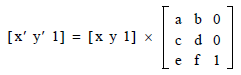
Здесь вы уже видите те числа a, b, c, d, e и f, о которых вы спрашивали.
Теперь, прежде чем принимать во внимание преобразования, специфичные для текста, вы должны принять во внимание манипуляции с текущей (независимой от текста) матрицей преобразования. Эта матрица управляется см операторы:
а б в г е ф см Измените текущую матрицу преобразования (CTM) путем объединения указанной матрицы (см. 8.3.2, «Пространства координат»). Хотя операнды задают матрицу, они должны быть записаны как шесть отдельных чисел, а не как массив.
(раздел 8.4.4, ISO 32000-1: 2008)
Это подразумевает, кстати, что вы должны рассмотреть все см операторы в настоящее время в действии, то есть все представлены с начала содержимого страницы, за исключением тех, которые были отменены путем восстановления прежнего графического состояния (см. операторы Q а также Q выдвижение и восстановление графических состояний, раздел 8.4.2, ISO 32000-1: 2008).
Только теперь вы можете рассмотреть текстовые матрицы преобразования:
В начале текстового объекта, Tm должна быть единичной матрицей; следовательно, источник текстового пространства должен быть первоначально таким же, как и в пользовательском пространстве. Операторы позиционирования текста, описанные в таблице 108, изменяют Tm и, таким образом, контролировать размещение глифов, которые впоследствии окрашены. Кроме того, операторы отображения текста, описанные в таблице 109, обновляют Tm (путем изменения его компонентов перевода e и f), чтобы учесть горизонтальное или вертикальное смещение каждого нарисованного глифа, а также любые символьные или межсимвольные параметры в текстовом состоянии.
Кроме того, в текстовом объекте соответствующий читатель должен отслеживать матрицу текстовой строки, Tlm, который фиксирует значение Tm в начале строки текста. Операторы позиционирования и отображения текста должны считывать и устанавливать Tlm в особых случаях, упомянутых в таблицах 108 и 109
(раздел 9.4.2, ISO 32000-1: 2008)
Таким образом, внутри текстового объекта вы должны отслеживать текстовую матрицу, которая в основном устанавливается с помощью Tm Оператор, который вы нашли с операндами, расположенными в матрице, как показано выше, но который также управляется как эффект других операторов позиционирования и отображения текста.
И еще есть дополнительные параметры, определяющие конечную позицию текста, параметры состояния текста Tfs (размер шрифта текста), Th (горизонтальное масштабирование) и Trise (текст взлета), ср. раздел 9.3.1, ISO 32000-1: 2008.
Концептуально все преобразование из текстового пространства в пространство устройства [или в вашем случае в пространство пользователя по умолчанию] может быть представлен матрицей рендеринга текста, Trm:
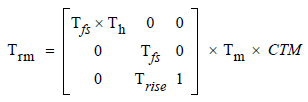
Trm временная матрица; концептуально, он пересчитывается перед тем, как каждый глиф раскрашивается во время операции показа текста.
(раздел 9.4.2, ISO 32000-1: 2008)
Таким образом, ваши координаты (x, y) концептуально являются результатом координат текстового пространства путем умножения на Trm:
[x, y, 1] = [xts, yts, 1] x Trm
где (xts, yts) равны (0, 0) в начале координат глифов. Для каждого напечатанного глифа у вас есть смещение глифа, чтобы добраться до точки, где будет расположен следующий источник глифа:

Текстовая матрица должна обновляться этими значениями смещения глифа следующим образом:
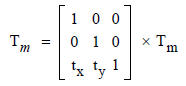
(раздел 9.4.4, ISO 32000-1: 2008)
Я процитировал несколько абзацев из текущей спецификации PDF ISO 32000-1: 2008. Я понимаю, что это предпочтительнее, чем использовать PDF Reference 1.4, который довольно древний; кроме того, он был назван «ненормативным по своему характеру» персоналом Adobe.
РЕДАКТИРОВАТЬ Некоторые уточнения в ответ на комментарии
пространство устройства и пространство пользователя, в чем их различие, не относится ли пространство устройства к отображению принтера / видео? а пространство пользователя способ преодолеть особенности каждого устройства? как страница пользователя, являющаяся страницей документа, которую я вижу?
Да, пространство устройства — это фиксированная система координат, в основном определяемая свойствами устройства под рукой. И да, пользовательское пространство является системой координат, независимой от целевого устройства. Но нет, это не «страница документа, которую вы видите», потому что вы видите ее на каком-то устройстве (или после обработки на каком-либо устройстве).
Система координат пространства пользователя — это независимая система координат, координаты точки которой могут быть переведены в координаты устройства посредством умножения матрицы на текущую матрицу преобразования (CTM).
UserCoords x CTM = DeviceCoords
Система координат пространства пользователя инициализируется в состояние, в котором запись CropBox в словаре страницы задает прямоугольник пользовательского пространства, соответствующий видимой области (см. выше) путем соответствующей инициализации CTM.
Но как уже говорит выбор слов («ток матрица преобразования «,» система координат инициализируется«), система координат пространства пользователя является динамичный, постоянно меняющийся система координат.
Пространство пользователя по умолчанию обеспечивает согласованное и надежное начальное место для описания страниц PDF независимо от используемого устройства вывода. При необходимости поток содержимого в формате PDF может изменить пространство пользователя, чтобы оно больше соответствовало его потребностям, применяя оператор преобразования координат, см (см. 8.4.4, «Операторы состояния графики»). Таким образом, то, что может показаться абсолютными координатами в потоке контента, не является абсолютным по отношению к текущей странице, потому что они выражены в системе координат, которая может скользить и уменьшаться или расширяться. Преобразование системы координат не только повышает независимость от устройства, но и само по себе является полезным инструментом.
(раздел 8.3.2.3, ISO 32000-1: 2008)
Таким образом, когда PdfReader натыкается на см Оператор с параметрами, представляющими некоторую матрицу M, изменяет CTM:
CTMnew = M x CTMold
и координаты, присутствующие в следующих операторах, интерпретируются согласно этой новой матрице CTMnew:
UserCoords x CTMnew = DeviceCoords
Так что теперь система координат пространства пользователя может сильно отличаться от своего прежнего состояния, масштабироваться, поворачиваться, наклоняться, что угодно.
Скорее всего, вас интересуют координаты в системе координат, в которой инициализируется пространство пользователя, то есть система координат устройства для виртуального устройства, для которого CTM инициализируется как единичная матрица.
где текстовое пространство и глиф пространство начинается и заканчивается.
Координаты текста указываются в текстовом пространстве. Преобразование из текстового пространства в пользовательское пространство определяется текстовой матрицей в сочетании с несколькими текстовыми параметрами в графическом состоянии (см. 9.4.2, «Операторы позиционирования текста»).
Текстовая матрица TM инициализируется как единичная матрица в начале текстового объекта, но изменяется во время выполнения текстовых операций, что наиболее заметно при использовании Tm оператор, неявно, когда вы используете другие. Эта матрица управляется матрицей TR, содержащей размер шрифта текстовых параметров, горизонтальное масштабирование и рост текста. Подробнее см. Матрицу рендеринга текста TRM выше. Таким образом,
DeviceCoords = UserCoords x CTM = TextCoords x TR x TM x CTM
Преобразование из глиф-пространства в текстовое пространство должно определяться матрицей шрифта. Для большинства типов шрифтов эта матрица должна быть предопределена для отображения 1000 единиц пространства глифов на 1 единицу текстового пространства; для шрифтов типа 3 матрица шрифтов должна быть явно указана в словаре шрифтов (см. 9.6.5, «Шрифты типа 3»).
Таким образом, это преобразование зависит от текущего шрифта. Матрица шрифтов FM из словаря шрифтов будет выглядеть следующим образом:
DeviceCoords = GlyphCoords x FM x TR x TM x CTM
Вы не хотите размещать координаты устройства одного сегмента глифа, поэтому эти координаты не интересны. Ширина глифа, тем не менее, должна интерпретироваться в пространстве глифа. Если, конечно, вы не имеете дело со шрифтами типа 3, это просто означает, что вы должны разделить их на 1000 …
И как параметры w0 и w1 развиваются во время рисования глифа? они изначально (0,0)
w0 и w1 обозначают горизонтальные и вертикальные смещения глифа. В режиме горизонтальной записи w0 — это ширина глифа, преобразованная в текстовый режим (то есть чаще всего просто делится на 1000), а w1 — 0. Для вертикальной записи текста проверьте разделы 9.2.4 и 9.7.4.3 в ISO 32000-1: 2008.
текстовое пространство имеет то же происхождение, что и первое пространство глифа? и они обновляются с рассчитанным (тх, ты)?
Так как координаты пространства глифа просто умножаются на матрицу шрифта, чтобы получить координаты текстового пространства и матрицу шрифта во всех случаях, но для шрифтов типа 3 просто сжимается с коэффициентом 1000, см. Выше, источник глифа отображается в текстовое пространство происхождение.
Но tx и ty используются для обновления самой текстовой матрицы. Таким образом, система координат текстового задания перемещается для каждого глифа и для каждого (не типа 3) источника глифа отображается на начало … слегка измененной системы координат текстового пространства.
Другие решения
Не стоит недооценивать масштаб этой задачи. Бит текстовой матрицы довольно прост и понятен. Трудным является сам текст.
Давайте начнем с вашего запроса — почему в каждой группе из четырех лидирует 00?
Ну, PDF не имеет стандартной кодировки текста — он имеет много, много и много. Вам нужно знать, какая кодировка для шрифта, прежде чем вы сможете декодировать текст.
Итак, в вашем примере:
BT
/F1 8.88 Tf
0 0 0 rg
0.9998 0 0 1 401.52 448.08 Tm
[<0014>-11<0015>-11<0013>-11<000F>-19<0014>-11<0019>] TJ
ET
Шрифт — бит / F1. Это имя, которое существует на странице (или его родителях) и относится к шрифту. Вам нужно найти шрифт и выяснить, что такое кодировка.
Учитывая содержание в вашем примере, я подозреваю, что кодировка является идентификационной и что четырехзначные шестнадцатеричные числа являются идентификаторами глифов внутри шрифта. Если это так, тогда у шрифта должна быть запись ToUnicode, которая позволит вам найти идентификатор глифа и вернуть символ Unicode.
Другие шрифты могут иметь или не иметь записи ToUnicode, и если это происходит, существует множество способов извлечь текст Unicode. Разные методы могут давать разные результаты, поэтому в спецификации PDF есть целый раздел, озаглавленный «Извлечение текстового содержимого», в котором подробно описывается порядок, в котором они должны выполняться.
Надеюсь, в вашей библиотеке PoDoFo должны быть методы для такого преобразования. Если нет, то задача будет довольно сложной, и я думаю, что вы должны рассмотреть некоторые другие варианты. Я написал код извлечения текста для нашей библиотеки ABCpdf .NET, и он занял несколько месяцев, а затем несколько лет настройки.