Использование побитового & amp; вместо оператора модуля для случайной выборки целых чисел из диапазона
Мне нужно, чтобы случайная выборка из равномерного распределения целых чисел в течение интервала [LB,UB] в C ++. Для этого я начну с «хорошего» генератора RN (из «Числовых рецептов», 3-е изд.), Который равномерно случайным образом выбирает 64-битные целые числа; давай называть это int64(),
Используя оператор мода, я могу выбрать из целых чисел в [LB,UB] от:
LB+int64()%(UB-LB+1);
Единственная проблема с использованием оператора mod — медлительность целочисленного деления. Итак, я тогда попробовал предложенный метод Вот, который:
LB + (int64()&(UB-LB))
Побитовый & метод примерно в 3 раза быстрее. Это очень важно для меня, потому что для одного из моих симуляций в C ++ нужно случайным образом выбрать около 20 миллионов целых чисел.
Но есть одна большая проблема. Когда я анализирую целые числа, выбранные с использованием побитового & метод, они не выглядят равномерно распределенными по интервалу [LB,UB], Целые числа действительно взяты из [LB,UB], но только из четных целых чисел в этом диапазоне. Например, вот гистограмма из 5000 целых чисел, взятая из [20,50] с использованием побитового & метод:
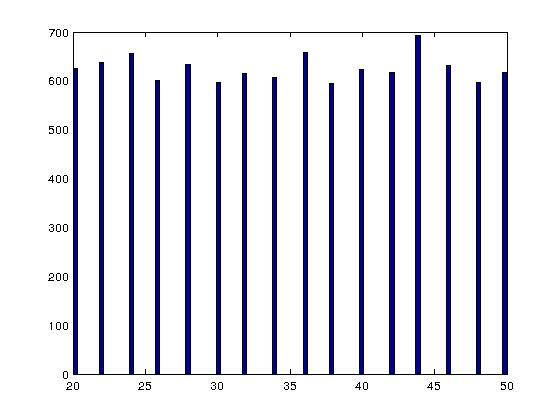
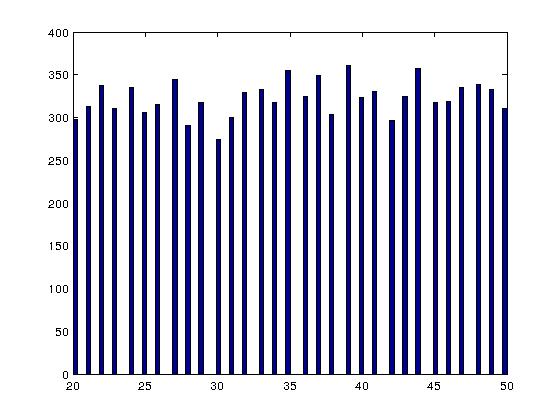
Для сравнения, вот как выглядит похожая гистограмма при использовании метода оператора mod, который, конечно, работает нормально:
Что не так с моим побитовым & метод? Есть ли способ изменить его так, чтобы за определенный интервал отбирались как четные, так и нечетные числа?
Решение
Побитовый & оператор просматривает каждую пару соответствующих битов своих операндов, выполняет and используя только эти два бита, и помещает этот результат в соответствующий бит результата.
Итак, если последний бит UB-LB 0, то последний бит результата 0, То есть если UB-LB Даже тогда каждый выход будет четным.
& не соответствует цели, если UB-LB+1 является степенью 2. Если вы хотите найти модуль, тогда нет общего ярлыка: компилятор уже реализует % самый быстрый способ это знает.
Обратите внимание, что я сказал нет генеральный ярлык. Для определенных значений UB-LB, известные во время компиляции, могут быть более быстрые способы. И если вы можете как-то организовать UB а также LB иметь значения, которые компилятор может вычислить во время компиляции, тогда он будет использовать их при написании %,
Кстати, используя % на самом деле не дает равномерно распределенных целых чисел по диапазону, если только размер диапазона не является степенью 2. В противном случае должно быть небольшое смещение в пользу определенных значений, потому что диапазон вашего int64() функция не может быть назначена одинаково в нужном диапазоне. Может случиться так, что смещение слишком мало, чтобы повлиять на вашу симуляцию в частности, но плохие генераторы случайных чисел в прошлом ломали случайные симуляции и будут делать это снова.
Если вы хотите равномерное распределение случайных чисел в произвольном диапазоне, используйте std::uniform_int_distribution из C ++ 11, или класс с тем же именем в Boost.
Другие решения
Это хорошо работает, если разница в диапазоне (UB-LB) 2N-1, но не будет работать хорошо, если, например, 2N.
Эти два значения эквивалентны только тогда, когда размер интервала равен степени двух. В общем у% х и у&(х-1) не одинаковы.
Например, x% 5 производит числа от 0 до 4 (или до -4, для отрицательного x), но x&4 выдает 0 или 4, а не 1, 2 или 3, из-за того, как работают побитовые операторы …