Интерпретация потребления памяти программой с использованием pugixml
У меня есть программа, которая анализирует файл XML размером ~ 50 МБ и извлекает данные во внутреннюю структуру объекта без ссылок на исходный файл XML. Когда я пытаюсь приблизительно оценить, сколько памяти мне нужно, я считаю 40 МБ.
Но моей программе нужно что-то вроде 350 МБ, и я пытаюсь выяснить, что происходит. я использую boost::shared_ptrтак что я не имею дело с необработанными указателями и, надеюсь, я не произвел утечки памяти.
Я пытаюсь написать, что я сделал, и я надеюсь, что кто-то может указать на проблемы в моем процессе, неправильные предположения и так далее.
Во-первых, как я измерил? я использовал htop чтобы выяснить, что моя память заполнена и процессы, использующие мой фрагмент кода, используют большую его часть. Чтобы подвести итог памяти разных потоков и получить более симпатичный вывод, я использовал http://www.pixelbeat.org/scripts/ps_mem.py что подтвердило мои наблюдения.
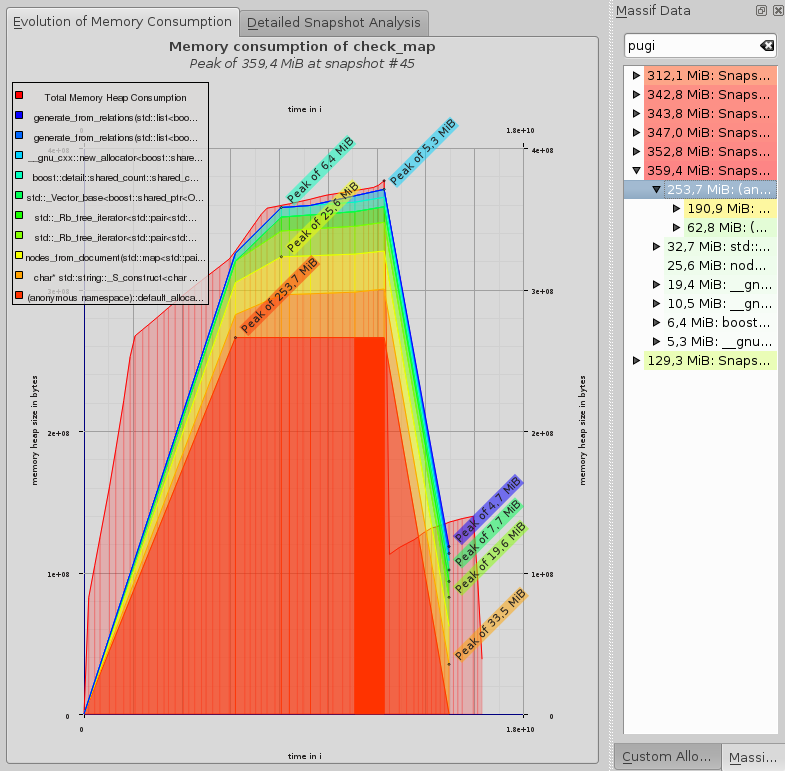
Я приблизительно оценил теоретическое потребление, чтобы понять, какой фактор лежит между потреблением и каким он должен быть, по крайней мере. Это 10. Так что я использовал valgrind --tool=massif проанализировать потребление памяти. Это показывает, что на пике 350 МБ 250 МБ используются чем-то xml_allocator который вытекает из pugixml библиотека. Я пошел в раздел моего кода, где я создаю pugi::xml_document и положить std::cout в деструктор объекта, чтобы подтвердить его освобождение, что происходит довольно рано в моей программе (в конце я сплю в течение 20 секунд, чтобы иметь достаточно времени для измерения потребления памяти, которое остается 350 МБ даже после появления вывода на консоль деструктора).
Теперь я понятия не имею, как это интерпретировать, и надеюсь, что кто-то может мне помочь, если я сделаю неправильные предположения или что-то подобное.
Внешний фрагмент кода с использованием pugixml похож на:
void parse( std::string filename, my_data_structure& struc )
{
pugi::xml_document doc;
pugi::xml_parse_result result = doc.load_file(filename.c_str());
for (pugi::xml_node node = doc.child("foo").child("bar"); node; node = node.next_sibling("bar"))
{
struc.hams.push_back( node.attribute("ham").value() );
}
}
И так как в моем коде я не храню pugixml элементы где-то (только фактические значения вытащил из него), я бы doc ожидать, чтобы освободить все ресурсы, когда функция parse осталось, но, глядя на график, я не могу сказать, где (на оси времени) это происходит.
Решение
Ваши предположения неверны.
Вот как можно оценить потребление памяти pugixml:
- Когда вы загружаете документ, весь текст документа загружается в память. Так что это 50 Мб для вашего файла. Это происходит как 1 выделение из xml_document :: load_file -> load_file_impl
- Кроме того, есть структура DOM, которая содержит ссылки на другие узлы и т. Д. Размер узла составляет 32 байта, размер атрибута составляет 20 байтов; это для 32-битных процессов, умножьте на 2 для 64-битных процессов. Это происходит как много выделений (каждое выделение примерно 32 КБ) из xml_allocator.
В зависимости от плотности узлов / атрибутов в вашем документе потребление памяти может варьироваться от, скажем, 110% от размера документа (т.е. 50 МБ -> 55 МБ) до, скажем, 600% (то есть 50 МБ -> 300 МБ) ,
Когда вы уничтожаете документ pugixml (вызывается xml_document dtor), данные освобождаются — однако, в зависимости от поведения кучи ОС, вы можете не увидеть, что они сразу же возвращаются в систему — они могут остаться в куче процесса. Чтобы убедиться, что вы можете попытаться выполнить синтаксический анализ снова и проверить, что пиковый объем памяти остается таким же после второго анализа.
Другие решения
Других решений пока нет …