Должен ли я «связать» & Quot; прядение & Quot; нить к определенному ядру?
Мое приложение содержит несколько критичных к задержке потоков, которые «вращаются», то есть никогда не блокируются.
Ожидается, что такой поток займет 100% одного ядра процессора. Однако, похоже, что современные операционные системы часто переносят потоки из одного ядра в другое. Так, например, с этим кодом Windows:
void Processor::ConnectionThread()
{
while (work)
{
Iterate();
}
}
Я не вижу ядра «100% занятых» в диспетчере задач, общая загрузка системы составляет 36-40%.
Но если я изменю это на это:
void Processor::ConnectionThread()
{
SetThreadAffinityMask(GetCurrentThread(), 2);
while (work)
{
Iterate();
}
}
Затем я вижу, что одно из ядер процессора занято на 100%, а общая нагрузка на систему снижена до 34-36%.
Значит ли это, что я должен стремиться SetThreadAffinityMask для «спина» темы? Если бы я улучшил добавление задержки SetThreadAffinityMask в этом случае? Что еще я должен сделать для «вращения» потоков, чтобы улучшить задержку?
Я в процессе переноса своего приложения на Linux, так что этот вопрос больше касается Linux, если это имеет значение.
обн нашел этот слайд, который показывает, что может помочь привязка потока занятости к ЦП:
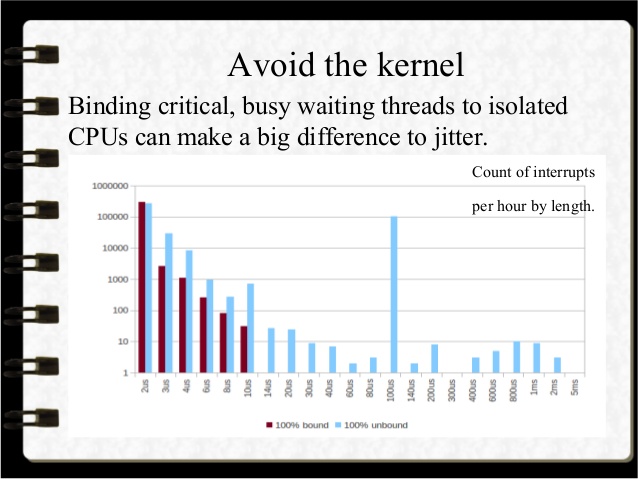
Решение
Запуск потока, привязанного к одному ядру, дает наибольшую задержку для этого потока в большинстве случаев, если это самая важная вещь в вашем коде.
Причины (R)
- ваш код может быть в вашем iCache
- предсказатели ветки настроены на ваш код
- ваши данные, вероятно, будут готовы в вашем dCache
- TLB указывает на ваш код и данные.
Если не
- Вы используете систему SMT (например, hyperthreaded), и в этом случае злой близнец будет «помогать» вам, заставляя ваш код стираться, ваши предсказатели ветвления будут настроены на его код, а его данные вытеснят вас из dCache, на его использование влияет TLB.
- Стоимость неизвестна, каждый кэш теряет стоимость ~ 4 нс, ~ 15 нс и ~ 75 нс для данных, это быстро достигает нескольких тысяч нс.
- Сохраняется для каждой причины R, упомянутой выше, которая все еще там.
- Если злой близнец Также просто раскручивать расходы должны быть значительно ниже.
- Или ваше разрешение прерывает ваше ядро, и в этом случае вы получаете те же проблемы и
- ваш TLB покраснел
- вы принимаете удар 1000 нс-20000 нс на переключение контекста, большинство должно быть в нижнем конце, если драйверы хорошо запрограммированы.
- Или вы позволяете ОС выключать ваш процесс, и в этом случае у вас возникают те же проблемы, что и у прерывания, только в верхнем конце диапазона.
- Выключение может также вызвать приостановку потока для всего среза, так как он может быть запущен только на одном (или двух) аппаратных потоках.
- Или вы используете любые системные вызовы, которые вызывают переключение контекста.
- Нет дискового ввода-вывода вообще.
- только асинхронный ввод-вывод еще.
- наличие более активных (без пауз) потоков, чем у ядер, увеличивает вероятность проблем.
Поэтому, если вам требуется задержка менее 100 нс, чтобы предотвратить взрыв приложения, вам нужно предотвратить или уменьшить влияние SMT, прерываний и переключения задач на вашем ядре.
Идеальным решением было бы Операционная система реального времени со статическим планированием. Это почти идеальный вариант для вашей цели, но это новый мир, если вы в основном занимались серверным и настольным программированием.
Недостатками фиксации резьбы на одном ядре являются:
- Это будет стоить некоторой общей пропускной способности.
- как некоторые потоки, которые могли бы работать, если бы контекст мог быть переключен.
- но задержка важнее в этом случае.
- Если поток отключается из контекста, потребуется некоторое время, прежде чем он может быть запланирован, возможно, на один или несколько временных интервалов, обычно 10-16 мс, что недопустимо в этом приложении.
- Привязка к ядру и его SMT уменьшит эту проблему, но не устранит ее. Каждое добавленное ядро уменьшит проблему.
- установка приоритета выше уменьшит проблему, но не устранит ее.
- Расписание с SCHED_FIFO и наивысшим приоритетом предотвратит большинство переключений контекста, прерывания могут по-прежнему вызывать временные переключения, как и некоторые системные вызовы.
- Если у вас есть установка с несколькими процессорами, вы можете получить эксклюзивное право собственности на один из процессоров через cpuset. Это мешает другим приложениям использовать его.
С помощью pthread_setschedparam с SCHED_FIFO и наивысшим приоритетом, работающим в SU и привязкой его к ядру, и его злой двойник должен обеспечить наилучшую задержку из всех этих, только операционная система реального времени может устранить все переключения контекста.
Другие ссылки:
Обсуждение прерывания.
Ваш Linux может принять то, что вы называете sched_setscheduler, с помощью SCHED_FIFO, но это требует, чтобы вы получили свой собственный PID, а не просто TID или что ваши потоки являются многозадачными.
Это не может быть идеальным, так как все ваши потоки будут переключаться только «добровольно», и таким образом устраняет гибкость, которую ядро может планировать.
Межпроцессное взаимодействие в 100ns
Другие решения
Прикрепление задачи к определенному процессору обычно дает лучшую производительность для задачи. Но при этом нужно учитывать множество нюансов и затрат.
При форсировании соответствия вы ограничиваете возможности планирования операционной системы. Вы увеличиваете конкуренцию за оставшиеся задачи. Так ВСЕ остальное на систему влияет, в том числе и на саму операционную систему. Вам также нужно учитывать, что если задачам необходимо взаимодействовать через память, а для привязок задано значение cpus, которые не разделяют кэш, вы можете значительно увеличить задержку для взаимодействия между задачами.
Тем не менее, одна из главных причин установки соответствия задач CPU — это то, что они обеспечивают более предсказуемое поведение кеша и tlb (буфер просмотра трансляций). Когда задача переключает ЦП, операционная система может переключить ее на ЦП, который не имеет доступа к кешу или ЦП последнего ЦП. Это может увеличить количество кешей для задачи. Это особенно проблема взаимодействия между задачами, так как для обмена данными между кэшами более высокого уровня и, наконец, самой плохой памятью требуется больше времени. Для измерения статистики кэша в Linux (производительность в целом) я рекомендую использовать перфорация.
Лучшее предложение — действительно измерить, прежде чем пытаться исправить сходство. Хороший способ определить латентность — использовать rdtsc инструкция (по крайней мере на x86). Это считывает источник времени процессора, который обычно дает высочайшую точность. Измерение по событиям даст примерно наносекундную точность.
volatile uint64_t rdtsc() {
register uint32_t eax, edx;
asm volatile (".byte 0x0f, 0x31" : "=d"(edx), "=a"(eax) : : );
return ((uint64_t) edx << 32) | (uint64_t) eax;
}
- Обратите внимание
rdtscИнструкция должна быть объединена с ограничителем нагрузки, чтобы обеспечить выполнение всех предыдущих инструкций (или использованиеrdtscp) - также обратите внимание — если
rdtscиспользуется без инвариантного источника времени (в Linuxgrep constant_tsc /proc/cpuinfo, вы можете получить ненадежные значения при изменении частоты, и если задача переключает процессор (источник времени)
Так что, в общем, да, установка сродства дает меньшую задержку, но это не всегда так, и при этом возникают очень серьезные затраты.
Некоторое дополнительное чтение …
Привязка потока к определенному ядру, вероятно, не лучший способ выполнить работу. Вы можете сделать это, это не повредит многоядерному процессору.
Действительно лучший способ уменьшить задержку — повысить приоритет процесса и потока (-ов) опроса. Обычно ОС прерывает ваши потоки сотни раз в секунду и позволяет другим потокам работать некоторое время. Ваш поток не может работать в течение нескольких миллисекунд.
Повышение приоритета уменьшит эффект (но не устранит его).
Узнайте больше о SetThreadPriority а также SetProcessPriorityBoost.
Там есть некоторые детали в документах, которые вам нужно понять.
Я столкнулся с этим вопросом, потому что имею дело с точно такой же проблемой дизайна. Я строю HFT-системы, где каждая наносекунда считается.
Прочитав все ответы, я решил реализовать и сравнить 4 различных подхода
- Ожидание занято без установленной близости
- заняты ожиданием с установленным сродством
- схема наблюдателя
- сигналы
Непобедимым победителем был «занятый ожиданием с набором близости». Насчет этого сомнений нет.
Теперь, как отмечали многие, не забудьте оставить пару ядер свободными, чтобы позволить ОС свободно работать.
Мое единственное беспокойство на данный момент заключается в том, если есть какой-то физический вред тем ядрам, которые работают на 100% часами.
Это просто глупо. Все, что он делает, это уменьшает гибкость планировщика. Если раньше он мог запускать его на том ядре, которое считал лучшим, то теперь это невозможно. Если планировщик не был написан идиотами, он только переместил бы поток в другое ядро, если бы у него была веская причина для этого.
Итак, вы просто говорите планировщику: «Даже если у вас есть действительно веская причина для этого, не делайте этого в любом случае». Почему ты так говоришь?