Должен ли я использовать, если маловероятно для серьезных ошибок сбоя?
Я часто пишу код, который выглядит примерно так:
if(a == nullptr) throw std::runtime_error("error at " __FILE__ ":" S__LINE__);
Должен ли я предпочесть обработку ошибок с if unlikely?
if unlikely(a == nullptr) throw std::runtime_error("error at " __FILE__ ":" S__LINE__);
Будет ли компилятор автоматически определять, какая часть кода должна быть кэширована, или это действительно полезная вещь? Почему я не вижу много людей, обрабатывающих подобные ошибки?
Решение
Должен ли я использовать «если маловероятно» для серьезных сбоев ошибок?
В таких случаях я бы предпочел переместить код, который выбрасывает в отдельную функцию extern, которая помечена как noreturn, Таким образом, ваш реальный код не будет «загрязнен» большим количеством кода, связанного с исключениями (или каким-либо другим кодом, вызывающим «тяжелый сбой»). Вопреки принятому ответу, вам не нужно отмечать его как cold, но вам действительно нужно noreturn заставить компилятор не пытаться сгенерировать код для сохранения регистров или любого другого состояния и, по сути, предположить, что после перехода туда нет пути назад.
Например, если вы пишете код таким образом:
#include <stdexcept>
#define _STR(x) #x
#define STR(x) _STR(x)
void test(const char* a)
{
if(a == nullptr)
throw std::runtime_error("error at " __FILE__ ":" STR(__LINE__));
}
компилятор сгенерирует много инструкций которые имеют дело с созданием и выбрасыванием этого исключения. Вы также вводите зависимость от std::runtime_error, Посмотрите, как будет выглядеть сгенерированный код если у вас есть только три чека в вашем test функция:
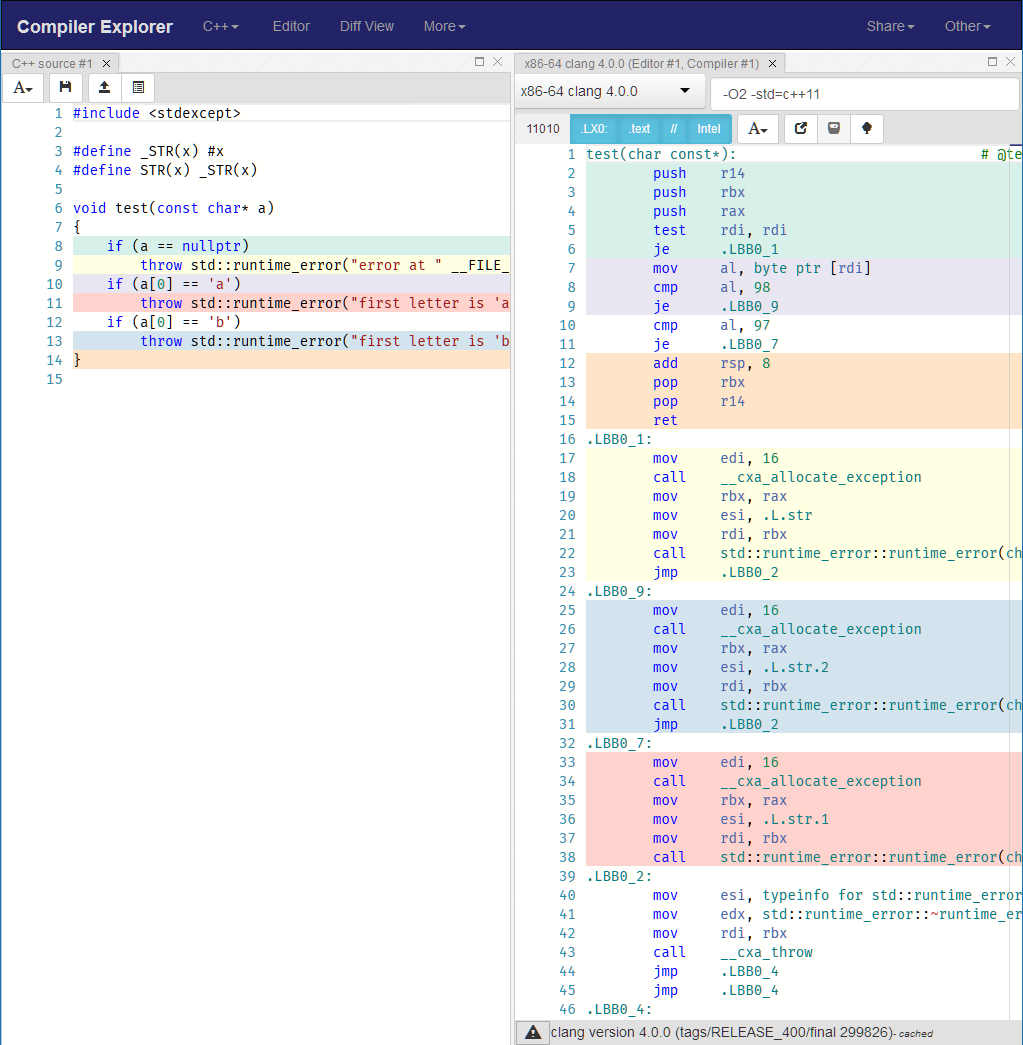
Первое улучшение: переместить его в автономная функция:
void my_runtime_error(const char* message);
#define _STR(x) #x
#define STR(x) _STR(x)
void test(const char* a)
{
if (a == nullptr)
my_runtime_error("error at " __FILE__ ":" STR(__LINE__));
}
таким образом вы избегаете генерации всего кода, связанного с исключениями, внутри вашей функции. Сразу сгенерированные инструкции стать проще и чище и уменьшите влияние на инструкции, генерируемые вашим реальным кодом, где вы выполняете проверки:
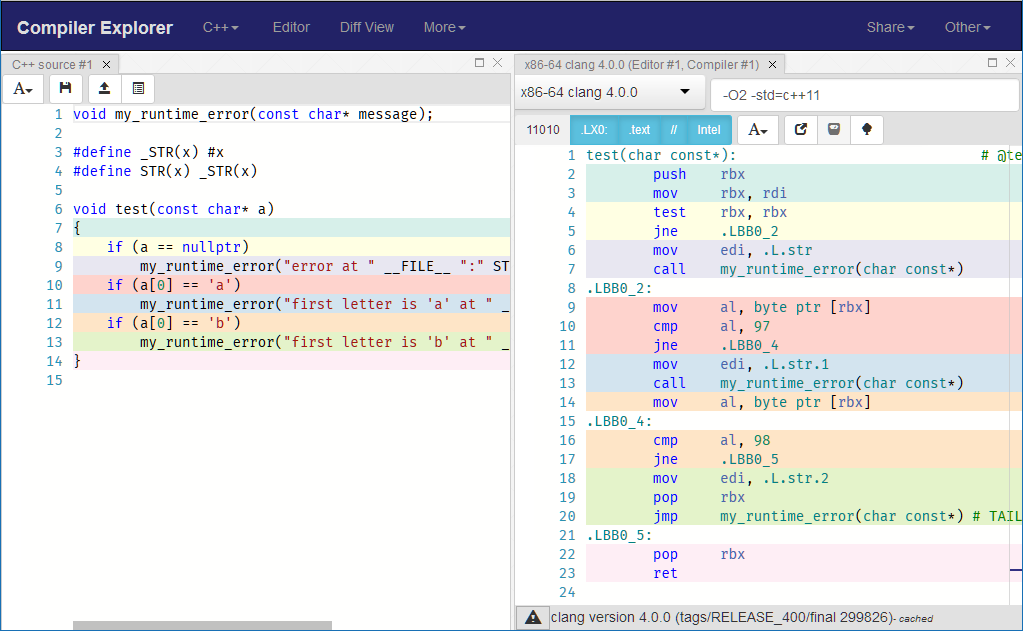
Есть еще возможности для улучшения. Так как вы знаете, что ваш my_runtime_error не вернется, вы должны сообщить об этом компилятору, чтобы он не нужно сохранять регистры перед вызовом my_runtime_error:
#if defined(_MSC_VER)
#define NORETURN __declspec(noreturn)
#else
#define NORETURN __attribute__((__noreturn__))
#endif
void NORETURN my_runtime_error(const char* message);
...
Когда ты использовать его несколько раз в вашем коде вы можете видеть, что сгенерированный код намного меньше и уменьшает влияние на инструкции, генерируемые вашим реальным кодом:
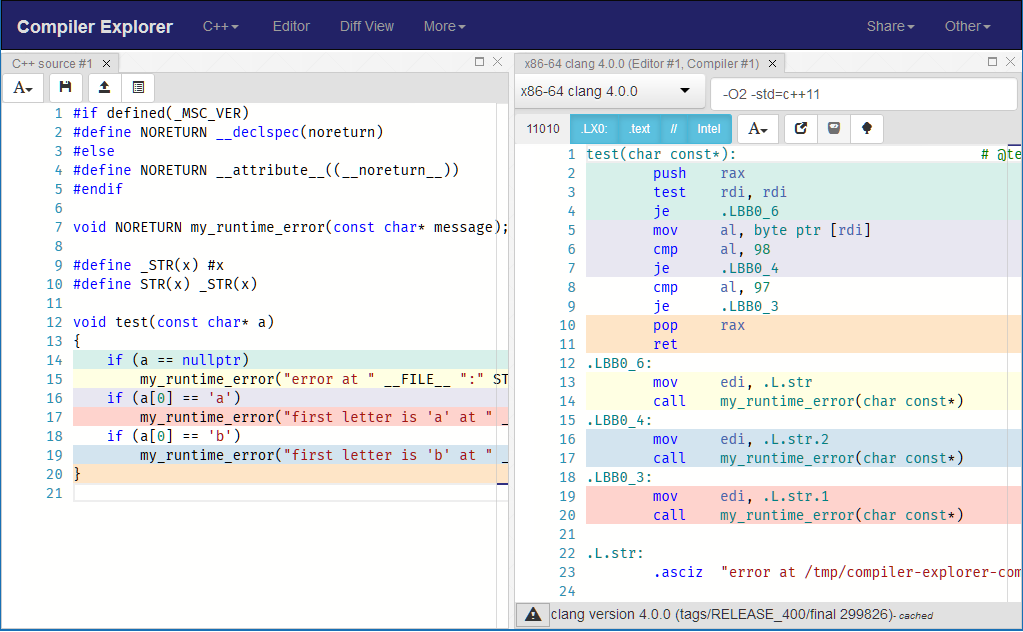
Как видите, компилятору не нужно сохранять регистры перед вызовом my_runtime_error,
Я бы также предложил против объединения строк ошибок с __FILE__ а также __LINE__ в монолитные строки сообщения об ошибке. Передайте их как отдельные параметры и просто сделайте макрос, который передает их!
void NORETURN my_runtime_error(const char* message, const char* file, int line);
#define MY_ERROR(msg) my_runtime_error(msg, __FILE__, __LINE__)
void test(const char* a)
{
if (a == nullptr)
MY_ERROR("error");
if (a[0] == 'a')
MY_ERROR("first letter is 'a'");
if (a[0] == 'b')
MY_ERROR("first letter is 'b'");
}
Может показаться, что для каждого вызова my_runtime_error генерируется больше кода (еще 2 инструкции в случае сборки x64), но общий размер на самом деле меньше, поскольку сохраненный размер в константных строках намного больше, чем дополнительный размер кода.
Кроме того, обратите внимание, что эти примеры кода хороши для того, чтобы продемонстрировать преимущества превращения вашей функции «жесткого сбоя» во внешнюю. Нужно для noreturn становится более очевидным в реальном коде, например:
#include <math.h>
#if defined(_MSC_VER)
#define NORETURN __declspec(noreturn)
#else
#define NORETURN __attribute__((noreturn))
#endif
void NORETURN my_runtime_error(const char* message, const char* file, int line);
#define MY_ERROR(msg) my_runtime_error(msg, __FILE__, __LINE__)
double test(double x)
{
int i = floor(x);
if (i < 10)
MY_ERROR("error!");
return 1.0*sqrt(i);
}
Сгенерированная сборка:
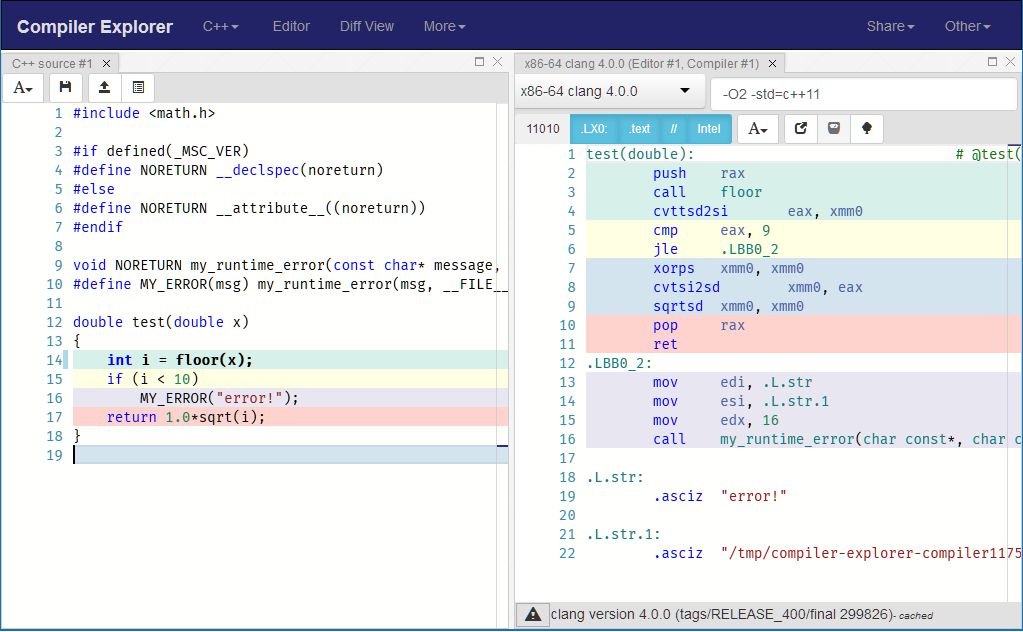
Попробуй удалить NORETURNили изменить __attribute__((noreturn)) в __attribute__((cold)) и вы увидите совершенно другая сгенерированная сборка!
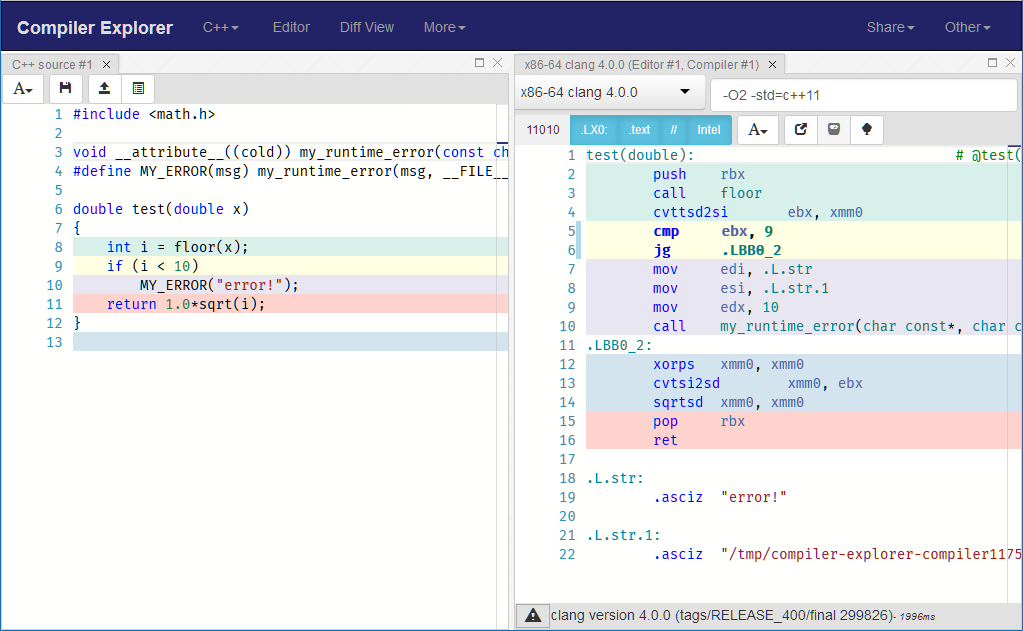
В качестве последнего пункта (что очевидно, ИМО и был опущен). Вы должны определить свой
my_runtime_error функция в некотором файле cpp. Поскольку это будет только одна копия, вы можете поместить любой код, который вы хотите, в эту функцию.
void NORETURN my_runtime_error(const char* message, const char* file, int line)
{
// you can log the message over network,
// save it to a file and finally you can throw it an error:
std::string msg = message;
msg += " at ";
msg += file;
msg += ":";
msg += std::to_string(line);
throw std::runtime_error(msg);
}
Еще один момент: Clang фактически признает, что этот тип функции выиграет от noreturn а также предупреждает об этом если -Wmissing-noreturn предупреждение было включено:
предупреждение: функция ‘my_runtime_error’ может быть объявлена с атрибутом
‘noreturn’ [-Wmissing-noreturn] {^
Другие решения
Да, вы можете сделать это. Но еще лучше, чтобы переместить throw в отдельную функцию, и пометьте его __attribute__((cold, noreturn)), Это избавит от необходимости говорить unlikely() на каждом сайте вызова и может улучшить генерацию кода, полностью переместив логику выдачи исключений за пределы «счастливого пути», улучшив эффективность кэширования инструкций и возможности встраивания.
Если вы предпочитаете использовать unlikely() для семантической нотации (чтобы облегчить чтение кода) это тоже хорошо, но само по себе это не оптимально.
Это зависит.
Прежде всего, вы определенно можете сделать это, и это, вероятно, (каламбур) не повредит производительности вашего приложения. Но учтите, что вероятные / маловероятные атрибуты зависят от компилятора и должны быть соответствующим образом оформлены.
Во-вторых, если вы хотите повысить производительность, результат будет зависеть от целевой платформы (и соответствующего бэкэнда компилятора). Если мы говорим об архитектуре x86 «по умолчанию», вы не получите большую прибыль от современных чипов — единственное изменение, которое эти атрибуты произведут, — это изменение макета кода (в отличие от более ранних времен, когда x86 поддерживал прогнозирование ветвей программного обеспечения) , Для небольших веток (как в вашем примере) это будет очень мало влиять на использование кэша и / или задержки внешнего интерфейса.
ОБНОВИТЬ:
Будет ли компилятор автоматически определять, какая часть кода должна быть кэширована, или это действительно полезная вещь?
На самом деле это очень широкая и сложная тема. Что будет делать компилятор, зависит от конкретного компилятора, его серверной части (целевой архитектуры) и параметров компиляции. Опять же, для x86, вот следующее правило (взято из Справочное руководство по оптимизации архитектур Intel® 64 и IA-32):
Правило 3. Кодирование сборки / компилятора (влияние M, обобщенность H) Организовать код в соответствии с
алгоритм прогнозирования статических ветвлений: сделать сквозной код, следующий за условной ветвью,
вероятная цель для ветви с прямой целью, и сделать сквозной код после условного
ветвь будет маловероятной целью для ветки с обратной целью.
Насколько я знаю, это единственное, что осталось от статического предсказания ветвлений в современном x86, и вероятные / маловероятные атрибуты могут использоваться только для «перезаписи» этого поведения по умолчанию.
Так как ты все равно «сильно разбиваешься», я бы пошел с
#include <cassert>
...
assert(a != nullptr);
Это не зависит от компилятора, должно давать вам почти оптимальную производительность, давать точку останова при работе в отладчике, генерировать дамп ядра, когда не в отладчике, и может быть отключено установкой NDEBUG символ препроцессора, который многие системы сборки делают по умолчанию для релизных сборок.