CUDA Thrust — подсчет подходящих подмассивов
Я пытаюсь выяснить, возможно ли эффективно рассчитать условную энтропию набора чисел с помощью CUDA. Вы можете рассчитать условную энтропию, разделив массив на окна, а затем посчитав количество подходящих подмассивов / подстрок для различной длины. Для каждой длины подмассива вы вычисляете энтропию, складывая совпадающие числа подмассивов, умноженные на журнал этих подсчетов. Тогда то, что вы получаете в качестве минимальной энтропии, является условной энтропией.
Чтобы дать более четкий пример того, что я имею в виду, вот полный расчет:
-
Исходный массив [1,2,3,5,1,2,5]. Предполагая, что размер окна равен 3, его следует разделить на пять окон: [1,2,3], [2,3,5], [3,5,1], [5,1,2] и [1 , 2,5].
-
Далее, глядя на каждое окно, мы хотим найти соответствующие подмассивы для каждой длины.
-
Подмассивы длины 1: [1], [2], [3], [5], [1]. Есть две цифры 1 и одна от другой. Таким образом, энтропия это лог (2)2 + 4(log (1) * 1) = 0,6.
-
Подмассивы длины 2 [1,2], [2,3], [3,5], [5,1] и [1,2]. Есть два [1,2] и четыре уникальных подмассива. Энтропия такая же, как длина 1, log (2)2 + 4(log (1) * 1) = 0,6.
-
Подмассивы длиной 3 являются полными окнами: [1,2,3], [2,3,5], [3,5,1], [5,1,2] и [1,2,5] , Все пять окон уникальны, поэтому энтропия равна 5 * (log (1) * 1) = 0.
-
Минимальная энтропия равна 0, что означает, что это условная энтропия для этого массива.
Это также может быть представлено в виде дерева, где счетчики в каждом узле представляют, сколько существует совпадений. Энтропия для каждой длины подмассива эквивалентна энтропии для каждого уровня дерева.
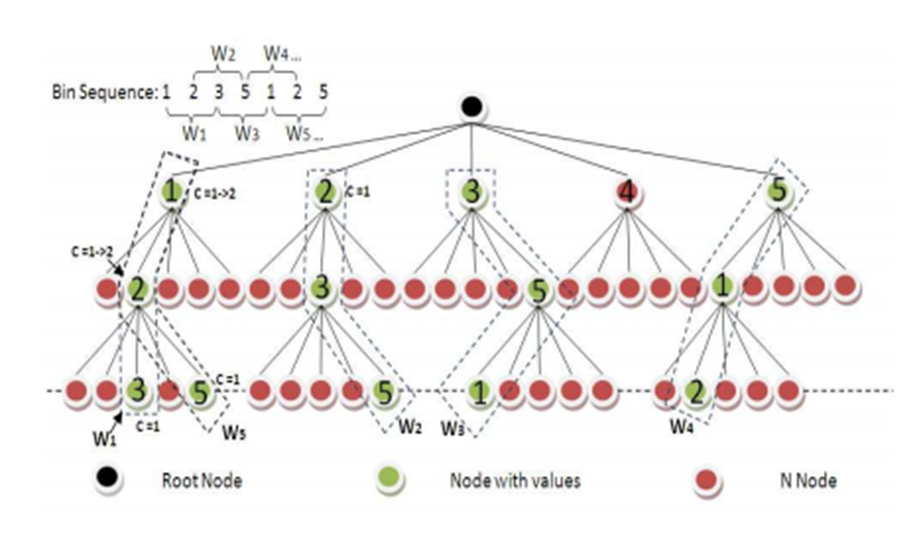
Если возможно, я бы хотел выполнить этот расчет сразу для нескольких массивов, а также параллельно выполнить сам расчет. У кого-нибудь есть предложения как это сделать? Может ли тяга быть полезной? Пожалуйста, дайте мне знать, если есть какая-либо дополнительная информация, которую я должен предоставить.
Решение
Я пытался решить вашу проблему с помощью тяги. Это работает, но это приводит к много упорных звонков.
Поскольку ваш входной размер довольно мал, вы должны обрабатывать несколько массивов параллельно.
Однако выполнение этого требует больших усилий по ведению бухгалтерского учета, вы увидите это в следующем коде.
Ваш диапазон ввода ограничен [1,5], что эквивалентно [0,4], Общая идея состоит в том, что (теоретически) любой кортеж из этого диапазона (например, {1,2,3} может быть представлен как число в базе 4 (например, 1+2*4+3*16 = 57).
На практике мы ограничены размером целочисленного типа. Для 32-битного целого числа без знака это приведет к максимальному размеру кортежа: 16, Это также максимальный размер окна, который может обрабатывать следующий код (изменение на 64-битное целое число без знака приведет к максимальному размеру кортежа: 32).
Давайте предположим, что входные данные структурированы так:
У нас есть 2 массивы, которые мы хотим обрабатывать параллельно, каждый массив имеет размер 5 и размер окна 3,
{{0,0,3,4,4},{0,2,1,1,3}}
Теперь мы можем сгенерировать все окна:
{{0,0,3},{0,3,4},{3,4,4}},{{0,2,1},{2,1,1},{1,1,3}}
Используя сумму префикса для каждого кортежа и применяя вышеупомянутое представление каждого кортежа в виде единого числа base-4, мы получаем:
{{0,0,48},{0,12,76},{3,19,83}},{{0,8,24},{2,6,22},{1,5,53}}
Теперь мы изменим порядок значений, чтобы у нас были числа, представляющие подмассив определенной длины рядом друг с другом:
{{0,0,3},{0,12,19},{48,76,83}},{0,2,1},{8,6,5},{24,22,53}}
Затем мы сортируем внутри каждой группы:
{{0,0,3},{0,12,19},{48,76,83}},{0,1,2},{5,6,8},{22,24,53}}
Теперь мы можем посчитать, как часто число встречается в каждой группе:
2,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1
Применение лог-формулы приводит к
0.60206,0,0,0,0,0
Теперь мы получаем минимальное значение для каждого массива:
0,0
#include <thrust/device_vector.h>
#include <thrust/copy.h>
#include <thrust/transform.h>
#include <thrust/iterator/counting_iterator.h>
#include <thrust/iterator/zip_iterator.h>
#include <thrust/functional.h>
#include <thrust/random.h>
#include <iostream>
#include <thrust/tuple.h>
#include <thrust/reduce.h>
#include <thrust/scan.h>
#include <thrust/gather.h>
#include <thrust/sort.h>
#include <math.h>
#include <chrono>
#ifdef PRINT_ENABLED
#define PRINTER(name) print(#name, (name))
#else
#define PRINTER(name)
#endif
template <template <typename...> class V, typename T, typename ...Args>
void print(const char* name, const V<T,Args...> & v)
{
std::cout << name << ":\t";
thrust::copy(v.begin(), v.end(), std::ostream_iterator<T>(std::cout, "\t"));
std::cout << std::endl;
}template <typename Integer, Integer Min, Integer Max>
struct random_filler
{
__device__
Integer operator()(std::size_t index) const
{
thrust::default_random_engine rng;
thrust::uniform_int_distribution<Integer> dist(Min, Max);
rng.discard(index);
return dist(rng);
}
};
template <std::size_t ArraySize,
std::size_t ArrayCount,
std::size_t WindowSize,
typename T,
std::size_t WindowCount = ArraySize - (WindowSize-1),
std::size_t PerArrayCount = WindowSize * WindowCount>
__device__ __inline__
thrust::tuple<T,T,T,T> calc_indices(const T& i0)
{
const T i1 = i0 / PerArrayCount;
const T i2 = i0 % PerArrayCount;
const T i3 = i2 / WindowSize;
const T i4 = i2 % WindowSize;
return thrust::make_tuple(i1,i2,i3,i4);
}
template <typename Iterator,
std::size_t ArraySize,
std::size_t ArrayCount,
std::size_t WindowSize,
std::size_t WindowCount = ArraySize - (WindowSize-1),
std::size_t PerArrayCount = WindowSize * WindowCount,
std::size_t TotalCount = PerArrayCount * ArrayCount
>
class sliding_window
{
public:
typedef typename thrust::iterator_difference<Iterator>::type difference_type;
struct window_functor : public thrust::unary_function<difference_type,difference_type>
{
__host__ __device__
difference_type operator()(const difference_type& i0) const
{
auto t = calc_indices<ArraySize, ArrayCount,WindowSize>(i0);
return thrust::get<0>(t) * ArraySize + thrust::get<2>(t) + thrust::get<3>(t);
}
};
typedef typename thrust::counting_iterator<difference_type> CountingIterator;
typedef typename thrust::transform_iterator<window_functor, CountingIterator> TransformIterator;
typedef typename thrust::permutation_iterator<Iterator,TransformIterator> PermutationIterator;
typedef PermutationIterator iterator;
sliding_window(Iterator first) : first(first){}
iterator begin(void) const
{
return PermutationIterator(first, TransformIterator(CountingIterator(0), window_functor()));
}
iterator end(void) const
{
return begin() + TotalCount;
}
protected:
Iterator first;
};
template <std::size_t ArraySize,
std::size_t ArrayCount,
std::size_t WindowSize,
typename Iterator>
sliding_window<Iterator, ArraySize, ArrayCount, WindowSize>
make_sliding_window(Iterator first)
{
return sliding_window<Iterator, ArraySize, ArrayCount, WindowSize>(first);
}template <typename KeyType,
std::size_t ArraySize,
std::size_t ArrayCount,
std::size_t WindowSize>
struct key_generator : thrust::unary_function<KeyType, thrust::tuple<KeyType,KeyType> >
{
__device__
thrust::tuple<KeyType,KeyType> operator()(std::size_t i0) const
{
auto t = calc_indices<ArraySize, ArrayCount,WindowSize>(i0);
return thrust::make_tuple(thrust::get<0>(t),thrust::get<2>(t));
}
};template <typename Integer,
std::size_t Base,
std::size_t ArraySize,
std::size_t ArrayCount,
std::size_t WindowSize>
struct base_n : thrust::unary_function<thrust::tuple<Integer, Integer>, Integer>
{
__host__ __device__
Integer operator()(const thrust::tuple<Integer, Integer> t) const
{
const auto i = calc_indices<ArraySize, ArrayCount, WindowSize>(thrust::get<0>(t));
// ipow could be optimized by precomputing a lookup table at compile time
const auto result = thrust::get<1>(t)*ipow(Base, thrust::get<3>(i));
return result;
}
// taken from http://stackoverflow.com/a/101613/678093
__host__ __device__ __inline__
Integer ipow(Integer base, Integer exp) const
{
Integer result = 1;
while (exp)
{
if (exp & 1)
result *= base;
exp >>= 1;
base *= base;
}
return result;
}
};
template <std::size_t ArraySize,
std::size_t ArrayCount,
std::size_t WindowSize,
typename T,
std::size_t WindowCount = ArraySize - (WindowSize-1),
std::size_t PerArrayCount = WindowSize * WindowCount>
__device__ __inline__
thrust::tuple<T,T,T,T> calc_sort_indices(const T& i0)
{
const T i1 = i0 % PerArrayCount;
const T i2 = i0 / PerArrayCount;
const T i3 = i1 % WindowCount;
const T i4 = i1 / WindowCount;
return thrust::make_tuple(i1,i2,i3,i4);
}
template <typename Integer,
std::size_t ArraySize,
std::size_t ArrayCount,
std::size_t WindowSize,
std::size_t WindowCount = ArraySize - (WindowSize-1),
std::size_t PerArrayCount = WindowSize * WindowCount>
struct pre_sort : thrust::unary_function<Integer, Integer>
{
__device__
Integer operator()(Integer i0) const
{
auto t = calc_sort_indices<ArraySize, ArrayCount,WindowSize>(i0);const Integer i_result = ( thrust::get<2>(t) * WindowSize + thrust::get<3>(t) ) + thrust::get<1>(t) * PerArrayCount;
return i_result;
}
};template <typename Integer,
std::size_t ArraySize,
std::size_t ArrayCount,
std::size_t WindowSize,
std::size_t WindowCount = ArraySize - (WindowSize-1),
std::size_t PerArrayCount = WindowSize * WindowCount>
struct generate_sort_keys : thrust::unary_function<Integer, Integer>
{
__device__
thrust::tuple<Integer,Integer> operator()(Integer i0) const
{
auto t = calc_sort_indices<ArraySize, ArrayCount,WindowSize>(i0);
return thrust::make_tuple( thrust::get<1>(t), thrust::get<3>(t));
}
};template<typename... Iterators>
__host__ __device__
thrust::zip_iterator<thrust::tuple<Iterators...>> zip(Iterators... its)
{
return thrust::make_zip_iterator(thrust::make_tuple(its...));
}struct calculate_log : thrust::unary_function<std::size_t, float>
{
__host__ __device__
float operator()(std::size_t i) const
{
return i*log10f(i);
}
};int main()
{
typedef int Integer;
typedef float Real;
const std::size_t array_count = ARRAY_COUNT;
const std::size_t array_size = ARRAY_SIZE;
const std::size_t window_size = WINDOW_SIZE;
const std::size_t window_count = array_size - (window_size-1);
const std::size_t input_size = array_count * array_size;
const std::size_t base = 4;
thrust::device_vector<Integer> input_arrays(input_size);
thrust::counting_iterator<Integer> counting_it(0);
thrust::transform(counting_it,
counting_it + input_size,
input_arrays.begin(),
random_filler<Integer,0,base>());
PRINTER(input_arrays);
const int runs = 100;
auto start = std::chrono::high_resolution_clock::now();
for (int k = 0 ; k < runs; ++k)
{
auto sw = make_sliding_window<array_size, array_count, window_size>(input_arrays.begin());
const std::size_t total_count = window_size * window_count * array_count;
thrust::device_vector<Integer> result(total_count);
thrust::copy(sw.begin(), sw.end(), result.begin());
PRINTER(result);auto ti_begin = thrust::make_transform_iterator(counting_it, key_generator<Integer, array_size, array_count, window_size>());
auto base_4_ti = thrust::make_transform_iterator(zip(counting_it, sw.begin()), base_n<Integer, base, array_size, array_count, window_size>());
thrust::inclusive_scan_by_key(ti_begin, ti_begin+total_count, base_4_ti, result.begin());
PRINTER(result);
thrust::device_vector<Integer> result_2(total_count);
auto ti_pre_sort = thrust::make_transform_iterator(counting_it, pre_sort<Integer, array_size, array_count, window_size>());
thrust::gather(ti_pre_sort,
ti_pre_sort+total_count,
result.begin(),
result_2.begin());
PRINTER(result_2);thrust::device_vector<Integer> sort_keys_1(total_count);
thrust::device_vector<Integer> sort_keys_2(total_count);
auto zip_begin = zip(sort_keys_1.begin(),sort_keys_2.begin());
thrust::transform(counting_it,
counting_it+total_count,
zip_begin,
generate_sort_keys<Integer, array_size, array_count, window_size>());
thrust::stable_sort_by_key(result_2.begin(), result_2.end(), zip_begin);
thrust::stable_sort_by_key(zip_begin, zip_begin+total_count, result_2.begin());
PRINTER(result_2);
thrust::device_vector<Integer> key_counts(total_count);
thrust::device_vector<Integer> sort_keys_1_reduced(total_count);
thrust::device_vector<Integer> sort_keys_2_reduced(total_count);
// count how often each sub array occurs
auto zip_count_begin = zip(sort_keys_1.begin(), sort_keys_2.begin(), result_2.begin());
auto new_end = thrust::reduce_by_key(zip_count_begin,
zip_count_begin + total_count,
thrust::constant_iterator<Integer>(1),
zip(sort_keys_1_reduced.begin(), sort_keys_2_reduced.begin(), thrust::make_discard_iterator()),
key_counts.begin()
);
std::size_t new_size = new_end.second - key_counts.begin();
key_counts.resize(new_size);
sort_keys_1_reduced.resize(new_size);
sort_keys_2_reduced.resize(new_size);
PRINTER(key_counts);
PRINTER(sort_keys_1_reduced);
PRINTER(sort_keys_2_reduced);auto log_ti = thrust::make_transform_iterator (key_counts.begin(), calculate_log());
thrust::device_vector<Real> log_result(new_size);
auto zip_keys_reduced_begin = zip(sort_keys_1_reduced.begin(), sort_keys_2_reduced.begin());
auto log_end = thrust::reduce_by_key(zip_keys_reduced_begin,
zip_keys_reduced_begin + new_size,
log_ti,
zip(sort_keys_1.begin(),thrust::make_discard_iterator()),
log_result.begin()
);
std::size_t final_size = log_end.second - log_result.begin();
log_result.resize(final_size);
sort_keys_1.resize(final_size);
PRINTER(log_result);
thrust::device_vector<Real> final_result(final_size);
auto final_end = thrust::reduce_by_key(sort_keys_1.begin(),
sort_keys_1.begin() + final_size,
log_result.begin(),
thrust::make_discard_iterator(),
final_result.begin(),
thrust::equal_to<Integer>(),
thrust::minimum<Real>()
);
final_result.resize(final_end.second-final_result.begin());
PRINTER(final_result);
}
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::high_resolution_clock::now() - start);
std::cout << "took " << duration.count()/runs << "milliseconds" << std::endl;
return 0;
}
компилировать используя
nvcc -std=c++11 conditional_entropy.cu -o benchmark -DARRAY_SIZE=1000 -DARRAY_COUNT=1000 -DWINDOW_SIZE=10 && ./benchmark
Эта конфигурация занимает 133 миллисекунды на моем графическом процессоре (GTX 680), то есть около 0,1 миллисекунды на массив.
Реализация может быть определенно оптимизирована, например, использование предварительно вычисленной таблицы поиска для преобразования base-4 и, возможно, некоторых из вызовов тяги можно избежать.
Другие решения