CUDA Profiler: рассчитать использование памяти и вычислить
Я пытаюсь установить два общих измерения для использования пропускной способности памяти и вычислить пропускную способность для моего приложения с ускорением на GPU, используя CUDA nsight profiler на Ubuntu. Приложение работает на графическом процессоре Tesla K20c.
Два измерения, которые я хочу, в некоторой степени сопоставимы с данными, приведенными на этом графике:
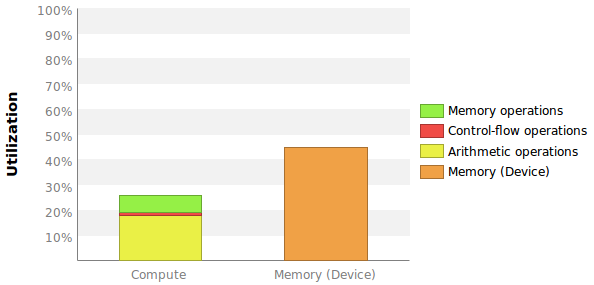
Проблема в том, что здесь нет точных цифр, и что более важно, я не знаю, как рассчитываются эти проценты.
Использование пропускной способности памяти
Профилировщик сообщает, что максимальная пропускная способность глобальной памяти моего графического процессора составляет 208 ГБ / с.
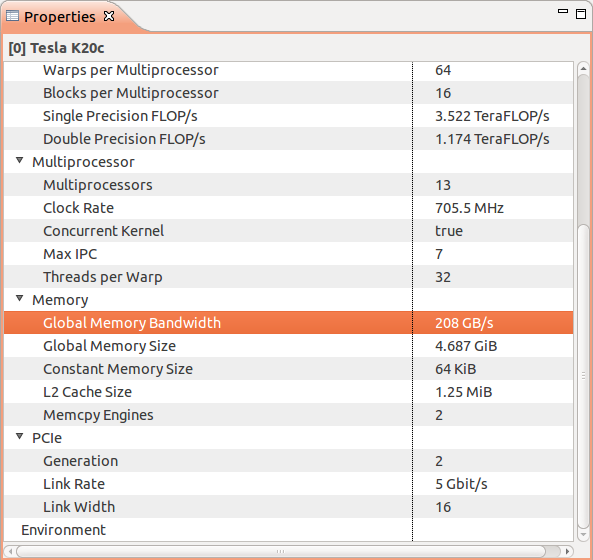
Это относится к BW памяти устройства или BW глобальной памяти? Это глобальный, но первый имеет больше смысла для меня.
Для моего ядра профилировщик говорит мне, что пропускная способность памяти устройства составляет 98,069 ГБ / с.

Предполагая, что максимум 208 ГБ / с относится к памяти устройства, могу ли я просто рассчитать использование BW памяти как 90.069 / 208 = 43%? Обратите внимание, что это ядро выполняется несколько раз без дополнительной передачи данных CPU-GPU. Поэтому система BW не важна.
Использование вычислительной пропускной способности
Я не совсем уверен, что лучший способ — это использовать Compute Throughput Utilization. Мое лучшее предположение состоит в том, чтобы использовать число инструкций за цикл до максимального количества инструкций за цикл. Профилировщик говорит мне, что максимальный IPC равен 7 (см. Рисунок выше).
Прежде всего, что это на самом деле означает? Каждый мультипроцессор имеет 192 ядра и, следовательно, максимум 6 активных деформаций. Не означает ли это, что максимальный IPC должен быть 6?
Профилировщик говорит мне, что мое ядро выпустило IPC = 1.144 и выполнило IPC = 0.907. Должен ли я вычислять коэффициент использования вычислений как 1,144 / 7 = 16% или 0,907 / 7 = 13% или ничего из этого?
Являются ли эти два измерения (использование памяти и вычислений) адекватным первым впечатлением от того, насколько эффективно мое ядро использует ресурсы? Или есть другие важные показатели, которые должны быть включены?
Дополнительный график
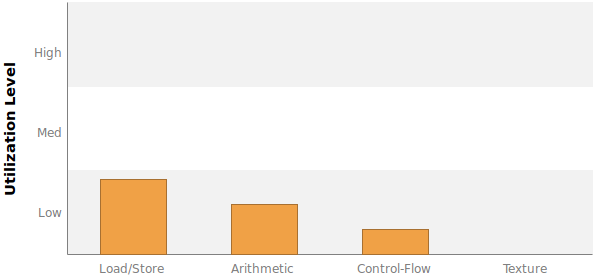
Решение
ПРИМЕЧАНИЕ. Я постараюсь обновить этот ответ для получения дополнительной информации в будущем. Я не думаю, что все отдельные компоненты расчетов хорошо видны в отчетах Visual Profiler.
Использование вычислительной техники
Это конвейерное использование логических каналов: памяти, потока управления и арифметики. У SM есть множество каналов исполнения, которые не являются документами. Если вы посмотрите на графики пропускной способности команд, вы сможете на высоком уровне определить, как рассчитать коэффициент использования. Вы можете прочитать документы архитектуры kepler или maxwell для получения дополнительной информации о конвейерах. Ядро CUDA — это маркетинговый термин для математического конвейера с плавающей запятой с целой / одинарной точностью.
Этот расчет не основан на IPC. Это основано на использовании трубопровода и циклах выпуска. Например, вы можете использовать их на 100%, если вы выполняете 1 инструкцию / цикл (никогда не повторяющиеся). Вы также можете быть на 100%, если вы выполняете инструкцию двойной точности с максимальной скоростью (зависит от графического процессора).
Использование пропускной способности памяти
Профилировщик рассчитывает использование L1, TEX, L2 и памяти устройства. Наибольшее значение отображается. Очень возможно иметь очень высокое использование пути передачи данных, но очень низкое использование полосы пропускания.
Также должна быть рассчитана причина задержки памяти. Очень легко иметь программу, связанную с задержкой памяти, но не связанную с использованием вычислений или пропускной способностью памяти.
Другие решения