CUDA: почему конкретная операция копирования памятки всегда стоит в 10 раз дороже, чем другие подобные
Я считаю, что следующий код выполняет типичную
- скопировать на устройство
- вызвать ядро
- скопировать обратно на хост
рабочий процесс.
-
Мне показалось очень странным то, что когда я использовал опцию Trace Application от NSight Profiler, в отчете с включенной «трассировкой стека» я обнаружил, что самой дорогой операцией является строка, выделенная жирным шрифтом, и только эта строка, в то время как другие операции memoCopy стоят почти 10% или меньше от этой операции memoCopy.
Это потому, что это первая строка после вызова ядра и, следовательно, профилировщик как-то включил стоимость некоторой синхронизации в стоимость этой конкретной операции memoCopy?
-
Для проблемы, подобной той, над которой я работаю, которая требует очень частой синхронизации и «возврата» результата на хост, может ли кто-нибудь предложить какой-нибудь общий совет относительно лучшей практики? Я думал, в частности, о двух вариантах, которые я не очень уверен, если в конечном итоге поможет
- использовать «нулевую копию» памяти (CUDA в Примере 11.2)
- создать как синхронизацию с использованием атомарных операций
{
int numP = p_psPtr->P.size();
int numL = p_psPtr->L.size();
// Out partition is in Unit of the Number of Particles
int block_dim = BLOCK_DIM_X;
int grid_dim = numP/block_dim + (numP%block_dim == 0 ? 0:1);
vector<Particle> pVec(p_psPtr->P.begin(), p_psPtr->P.end());
Particle *d_part_arr = 0;
Particle *part_arr = pVec.data();
HANDLE_ERROR(cudaMalloc((void**)&d_part_arr, numP * sizeof(Particle)));
HANDLE_ERROR(cudaMemcpy(d_part_arr, part_arr, numP * sizeof(Particle), cudaMemcpyHostToDevice));
vector<SpringLink> lVec(p_psPtr->L.begin(), p_psPtr->L.end());
SpringLink *d_link_arr = 0;
SpringLink *link_arr = lVec.data();
HANDLE_ERROR(cudaMalloc((void**)&d_link_arr, numL * sizeof(SpringLink)));
HANDLE_ERROR(cudaMemcpy(d_link_arr, link_arr, numL * sizeof(SpringLink), cudaMemcpyHostToDevice));
Point3D *d_oriPos_arr = 0;
Point3D *oriPos_arr = p_originalPos.data();
HANDLE_ERROR(cudaMalloc((void**)&d_oriPos_arr, numP * sizeof(Point3D)));
HANDLE_ERROR(cudaMemcpy(d_oriPos_arr, oriPos_arr, numP * sizeof(Point3D), cudaMemcpyHostToDevice));
Vector3D *d_oriVel_arr = 0;
Vector3D *oriVel_arr = p_originalVel.data();
HANDLE_ERROR(cudaMalloc((void**)&d_oriVel_arr, numP * sizeof(Vector3D)));
HANDLE_ERROR(cudaMemcpy(d_oriVel_arr, oriVel_arr, numP * sizeof(Vector3D), cudaMemcpyHostToDevice));
Point3D *d_updPos_arr = 0;
Point3D *updPos_arr = p_updatedPos.data();
HANDLE_ERROR(cudaMalloc((void**)&d_updPos_arr, numP * sizeof(Point3D)));
HANDLE_ERROR(cudaMemcpy(d_updPos_arr, updPos_arr, numP * sizeof(Point3D), cudaMemcpyHostToDevice));
Vector3D *d_updVel_arr = 0;
Vector3D *updVel_arr = p_updatedVel.data();
HANDLE_ERROR(cudaMalloc((void**)&d_updVel_arr, numP * sizeof(Vector3D)));
HANDLE_ERROR(cudaMemcpy(d_updVel_arr, updVel_arr, numP * sizeof(Vector3D), cudaMemcpyHostToDevice));
int *d_converged_arr = 0;
int *converged_arr = &p_converged[0];
HANDLE_ERROR(cudaMalloc((void**)&d_converged_arr, numP * sizeof(int)));
HANDLE_ERROR(cudaMemcpy(d_converged_arr, converged_arr, numP * sizeof(int), cudaMemcpyHostToDevice));
// Run the function on the device
handleParticleKernel<<<grid_dim, block_dim>>>(d_part_arr, d_link_arr, numP,
d_oriPos_arr, d_oriVel_arr, d_updPos_arr, d_updVel_arr,
d_converged_arr, p_innerLoopIdx, p_dt);
**HANDLE_ERROR(cudaMemcpy(oriPos_arr, d_oriPos_arr, numP * sizeof(Point3D), cudaMemcpyDeviceToHost));**
HANDLE_ERROR(cudaMemcpy(oriVel_arr, d_oriVel_arr, numP * sizeof(Vector3D), cudaMemcpyDeviceToHost));
HANDLE_ERROR(cudaMemcpy(updPos_arr, d_updPos_arr, numP * sizeof(Point3D), cudaMemcpyDeviceToHost));
HANDLE_ERROR(cudaMemcpy(updVel_arr, d_updVel_arr, numP * sizeof(Vector3D), cudaMemcpyDeviceToHost));
HANDLE_ERROR(cudaMemcpy(converged_arr, d_converged_arr, numP * sizeof(int), cudaMemcpyDeviceToHost));
}
Решение
Что конкретно cudaMemcpy вызов занимает больше времени, потому что он ждет, пока ваше ядро не завершится. Если вы добавите в cudaDeviceSynchronize после ядра, ваше предполагаемое время выполнения этого cudaMemcpy вызов должен соответствовать всем остальным. (Конечно, это дополнительное время, которое вы видите, будет потрачено на cudaDeviceSynchronize вызов).
Тем не менее, время, которое вы проводите в cudaDeviceSynchronize это что-то вроде фундаментальной цены, которую вы не можете обойти; если вам нужно использовать вывод из вашего ядра, то вам придется подождать, пока ядро не выполнится. Поскольку запуск ядра выполняется асинхронно, вы можете выполнять несвязанные операторы во время работы ядра; однако, в вашем случае, следующий вызов — копирование одного из выходов вашего ядра в память хоста, поэтому вам нужно дождаться завершения работы ядра, чтобы получить данные.
Если ваша программа позволяет, вы можете попытаться разбить запуск ядра и передачу памяти на куски и запуск их с использованием разных потоков, хотя жизнеспособность этого зависит от нескольких факторов (то есть ваше ядро может не разлагаться должным образом на независимые части). Если вы пойдете по этому пути, лучший сценарий будет такой (взят из CUDA Best Practices Docs)
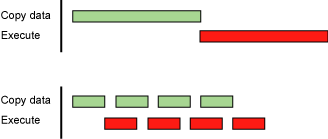
Это позволит вам перекрывать передачу данных с выполнением ядра, что позволяет скрыть некоторые расходы на передачу данных. Вы можете добиться аналогичной асинхронности с нулевым копированием, просто предупредите, что такие передачи не кэшируются, поэтому в зависимости от ваших шаблонов доступа к ядру вы можете получить меньшую пропускную способность.
Другие решения
Других решений пока нет …