Boost Spirit: медленная оптимизация при разборе
Я новичок в духе и для повышения в целом. Я пытаюсь проанализировать раздел файла VRML, который выглядит следующим образом:
point
[
#coordinates written in meters.
-3.425386e-001 -1.681608e-001 0.000000e+000,
-3.425386e-001 -1.642545e-001 0.000000e+000,
-3.425386e-001 -1.603483e-001 0.000000e+000,
Комментарий, который начинается с # не является обязательным.
Я написал грамматику, которая отлично работает, но процесс разбора занимает много времени. Я хотел бы оптимизировать его, чтобы он работал намного быстрее. Мой код выглядит так:
struct Point
{
double a;
double b;
double c;
Point() : a(0.0), b(0.0), c(0.0){}
};
BOOST_FUSION_ADAPT_STRUCT
(
Point,
(double, a)
(double, b)
(double, c)
)
namespace qi = boost::spirit::qi;
namespace repo = boost::spirit::repository;
template <typename Iterator>
struct PointParser :
public qi::grammar<Iterator, std::vector<Point>(), qi::space_type>
{
PointParser() : PointParser::base_type(start, "PointGrammar")
{
singlePoint = qi::double_>>qi::double_>>qi::double_>>*qi::lit(",");
comment = qi::lit("#")>>*(qi::char_("a-zA-Z.") - qi::eol);
prefix = repo::seek[qi::lexeme[qi::skip[qi::lit("point")>>qi::lit("[")>>*comment]]];
start %= prefix>>qi::repeat[singlePoint];
//BOOST_SPIRIT_DEBUG_NODES((prefix)(comment)(singlePoint)(start));
}
qi::rule<Iterator, Point(), qi::space_type> singlePoint;
qi::rule<Iterator, qi::space_type> comment;
qi::rule<Iterator, qi::space_type> prefix;
qi::rule<Iterator, std::vector<Point>(), qi::space_type> start;
};
Раздел, который я собираюсь проанализировать, расположен в середине входного текста, поэтому мне нужно пропустить часть текста, чтобы добраться до него. Я реализовал это с помощью Сделки РЕПО :: искать. Это лучший способ?
Я запускаю парсер следующим образом:
std::vector<Point> points;
typedef PointParser<std::string::const_iterator> pointParser;
pointParser g2;
auto start = ch::high_resolution_clock::now();
bool r = phrase_parse(Data.begin(), Data.end(), g2, qi::space, points);
auto end = ch::high_resolution_clock::now();
auto duration = ch::duration_cast<boost::chrono::milliseconds>(end - start).count();
Для анализа около 80 тыс. Записей во входном тексте требуется около 2,5 секунд, что довольно медленно для моих нужд. Мой вопрос, есть ли способ написать правила синтаксического анализа более оптимизированным способом, чтобы сделать это (намного) быстрее? Как я могу улучшить эту реализацию в целом?
Я новичок в Духе, поэтому некоторые объяснения будут высоко оценены.
Решение
Я подключил вашу грамматику в верньер бенчмарк и сгенерированные равномерно случайные входные данные ~ 85k строк (скачать: http://stackoverflow-sehe.s3.amazonaws.com/input.txt, 7,4 МБ).
- Вы измеряете время в сборке релиза?
- Вы используете медленный ввод файла?
При чтении файла заранее я получаю время ~ 36ms разобрать всю кучу.
clock resolution: mean is 17.616 ns (40960002 iterations)
benchmarking sample
collecting 100 samples, 1 iterations each, in estimated 3.82932 s
mean: 36.0971 ms, lb 35.9127 ms, ub 36.4456 ms, ci 0.95
std dev: 1252.71 μs, lb 762.716 μs, ub 2.003 ms, ci 0.95
found 6 outliers among 100 samples (6%)
variance is moderately inflated by outliers
Код: см. Ниже.
Заметки:
-
Вы, кажется, противоречат использованию шкиперов и ищите вместе. Я бы предложил вам упростить
prefix:comment = '#' >> *(qi::char_ - qi::eol); prefix = repo::seek[ qi::lit("point") >> '[' >> *comment ];prefixбудет использовать пробел и игнорировать любые подходящие атрибуты (из-за правила, объявленного типом). Делатьcommentнеявно лексема удалив шкипера из декларации правила:// implicit lexeme: qi::rule<Iterator> comment;Заметка Увидеть Повысьте проблемы с капитаном для получения дополнительной справочной информации.
#include <boost/fusion/adapted/struct.hpp>
#include <boost/spirit/include/qi.hpp>
#include <boost/spirit/repository/include/qi_seek.hpp>
namespace qi = boost::spirit::qi;
namespace repo = boost::spirit::repository;
struct Point { double a = 0, b = 0, c = 0; };
BOOST_FUSION_ADAPT_STRUCT(Point, a, b, c)
template <typename Iterator>
struct PointParser : public qi::grammar<Iterator, std::vector<Point>(), qi::space_type>
{
PointParser() : PointParser::base_type(start, "PointGrammar")
{
singlePoint = qi::double_ >> qi::double_ >> qi::double_ >> *qi::lit(',');
comment = '#' >> *(qi::char_ - qi::eol);
prefix = repo::seek[
qi::lit("point") >> '[' >> *comment
];
//prefix = repo::seek[qi::lexeme[qi::skip[qi::lit("point")>>qi::lit("[")>>*comment]]];
start %= prefix >> *singlePoint;
//BOOST_SPIRIT_DEBUG_NODES((prefix)(comment)(singlePoint)(start));
}
private:
qi::rule<Iterator, Point(), qi::space_type> singlePoint;
qi::rule<Iterator, std::vector<Point>(), qi::space_type> start;
qi::rule<Iterator, qi::space_type> prefix;
// implicit lexeme:
qi::rule<Iterator> comment;
};
#include <nonius/benchmark.h++>
#include <nonius/main.h++>
#include <boost/iostreams/device/mapped_file.hpp>
static boost::iostreams::mapped_file_source src("input.txt");
NONIUS_BENCHMARK("sample", [](nonius::chronometer cm) {
std::vector<Point> points;
using It = char const*;
PointParser<It> g2;
cm.measure([&](int) {
It f = src.begin(), l = src.end();
return phrase_parse(f, l, g2, qi::space, points);
bool ok = phrase_parse(f, l, g2, qi::space, points);
if (ok)
std::cout << "Parsed " << points.size() << " points\n";
else
std::cout << "Parsed failed\n";
if (f!=l)
std::cout << "Remaining unparsed input: '" << std::string(f,std::min(f+30, l)) << "'\n";
assert(ok);
});
})
График:
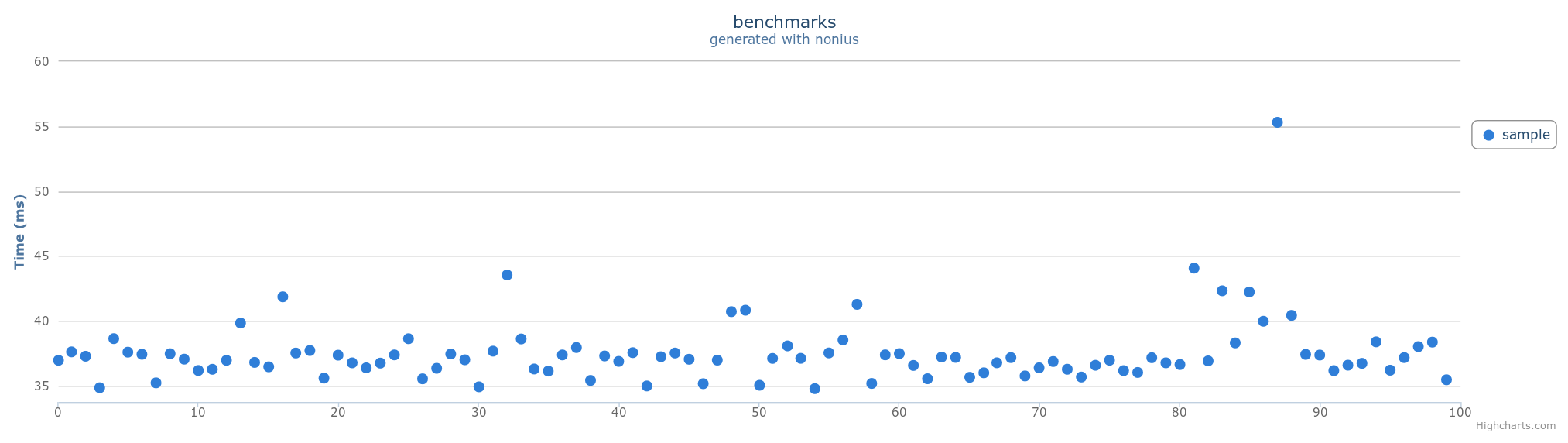
Еще один прогон выходных, live:
- http://stackoverflow-sehe.s3.amazonaws.com/30dd790b-8b52-4eab-a130-8d6896207b2f.html (нажмите на все отдельные образцы)
Другие решения
Других решений пока нет …